卷积神经网络




为什么大图像需要卷积¶

在实际场景中,通常需要更大的输入图像和更深的网络结构。
输入图像大小为1000x1000x3,第一层隐藏层神经元数量为1000
第一层权重的数量级为 109,参数过多会导致过拟合
卷积神经网络可以有效减少权重数量。
对比密集连接和卷积连接¶





人类视觉中的光感受器通路¶

每只眼睛大约包含1.25亿个视杆细胞和600万个视锥细胞。来自光感受器的信号在离开眼睛之前由大约1000万个水平细胞、无长突细胞和双极细胞处理,最后通过构成视神经的120万个神经节细胞的轴突离开。水平细胞和无长突细胞的横向连接为双极细胞提供了一个类似于两个同心圆盘的感受野。
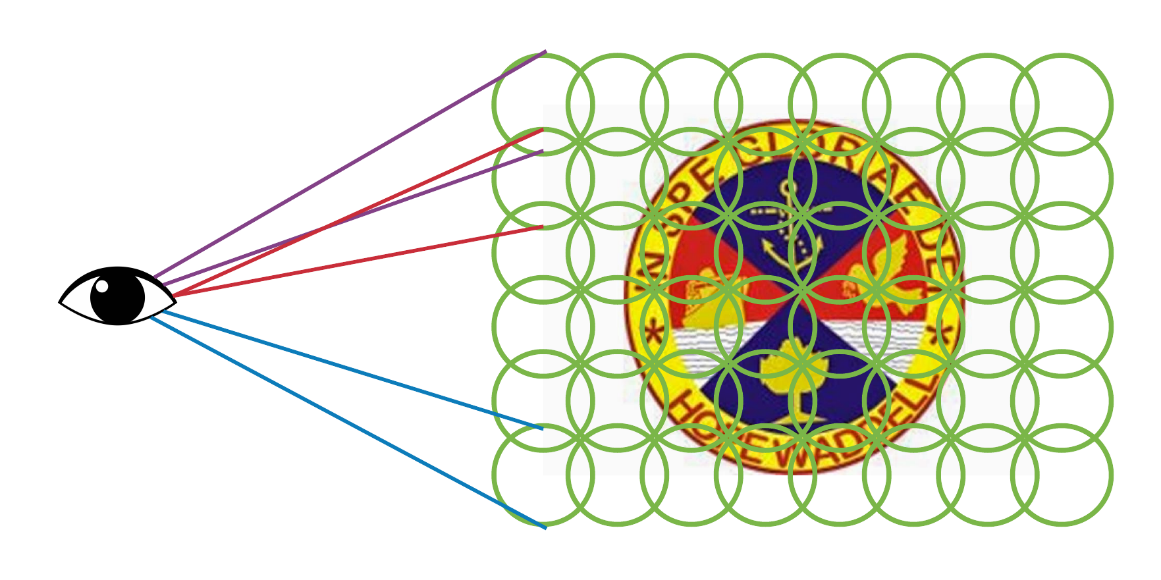
定义视网膜上的感受野¶

在生物视觉通路中,视网膜上的光感受器通过接收光线并将其转换为输出神经信号,影响许多神经节细胞、外侧膝状体核和视觉皮层中的神经细胞。不同区域的光感受器影响特定的神经节细胞以执行特定功能。直接或间接影响特定神经细胞的整个光感受器细胞群被称为该特定神经细胞的感受野。
中心-周边感受野动态¶

中心周边感受野由光感受器池生成,视网膜双极细胞和神经节细胞的中心开启(on-center)和中心关闭(off-center)感受野是由反应性光感受器群形成的。
光感受器可以激活(蓝色显示)或抑制(紫色显示)下游的双极细胞。对于中心双极细胞,照射在中心开启光感受器上的光会激活它们,而周围的光感受器则被抑制。对于中心关闭双极细胞,中心光是抑制性的,而周边光是兴奋性的。

视网膜LGN和皮层内的分层处理¶

生物视觉系统大致可分为三层:
视网膜中的光感受器细胞仅接收视野中一小块区域的光。这一小块区域定义了光感受器的感受野。感受野的双极细胞可以作为一个整体比较光感受器的神经信号,以检测明暗区域之间的空间关系,然后将结果报告给神经节细胞。
神经节细胞对神经信号进行再处理并汇总到外侧膝状体核。
最终,初级视觉皮层整合外侧膝状体核报告的神经信号,以在大脑中实现更高层次的图像和理解。

复杂细胞和超复杂细胞的出现¶

简单细胞形成复杂细胞,它们对光的方向和运动做出反应。它逐渐变得越来越复杂,最终形成所谓的超复杂细胞,它们可以对端点的移动做出反应,并使皮层能够识别角、形状等。
一般来说,复杂的感受野形状由简单的感受野组成。例如,连接一系列同心感受器可以创建一个能检测直线的复杂感受野。复杂感受野是初级视觉皮层中能够检测线条方向的细胞的特征。皮层处理的一个一般特征:随着深入神经结构,感受野变得越来越复杂,神经元能够对更高阶、更抽象的特征刺激做出反应。

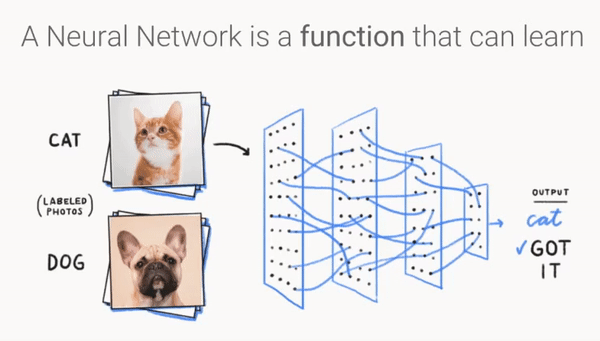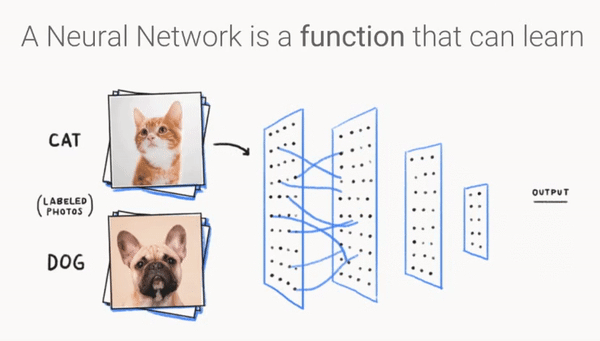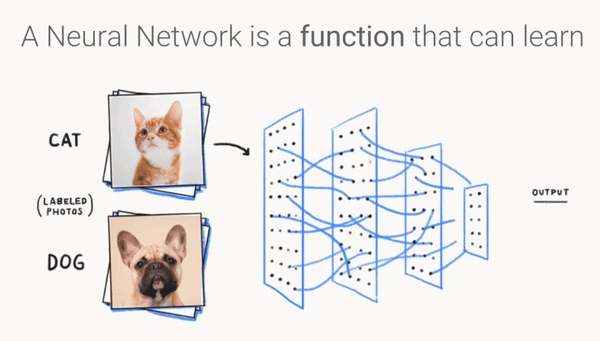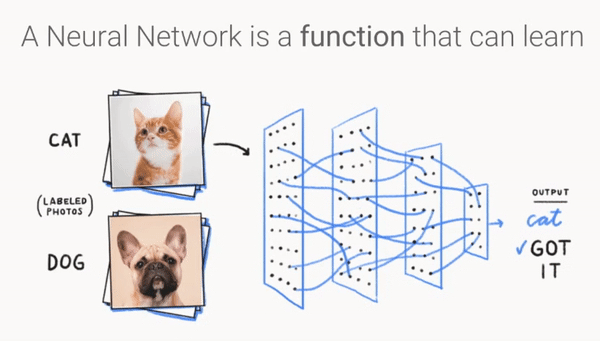

卷积神经网络结构¶
CNN架构的核心构建块¶

卷积网络由卷积层、池化层和全连接层组成。
倾向于小卷积、大深度、全卷积
一个卷积块由连续的M个卷积层和b个池化层组成(M通常为2~5,b为0或1)。在卷积网络中,可以堆叠N个连续的卷积块,然后连接K个全连接层(N一般为1~100或更多;K一般为0~2)。
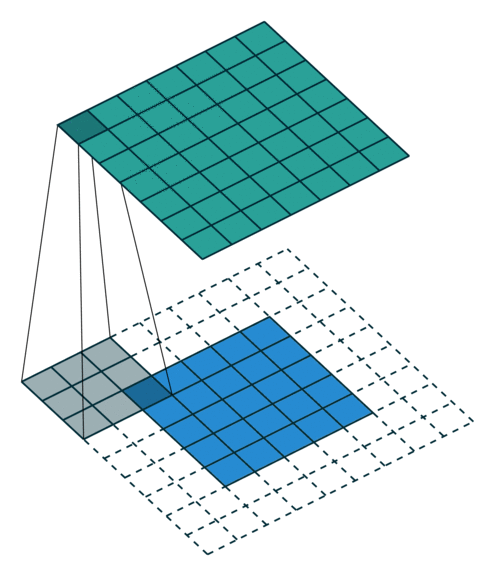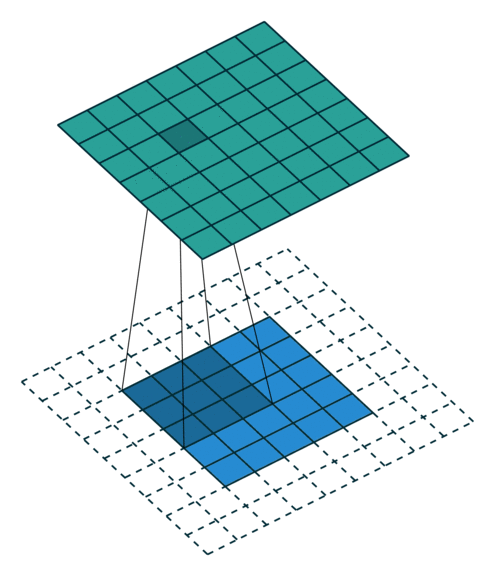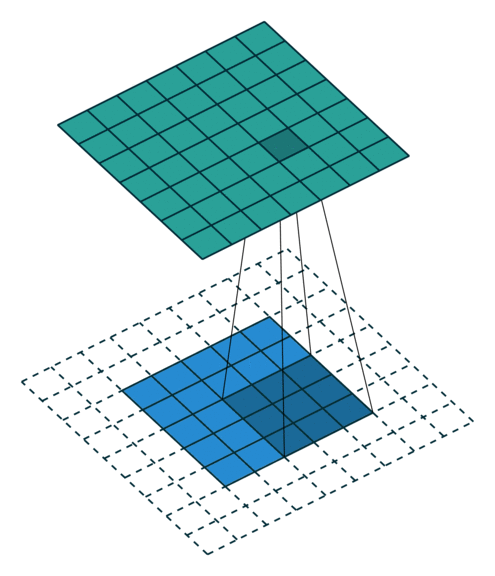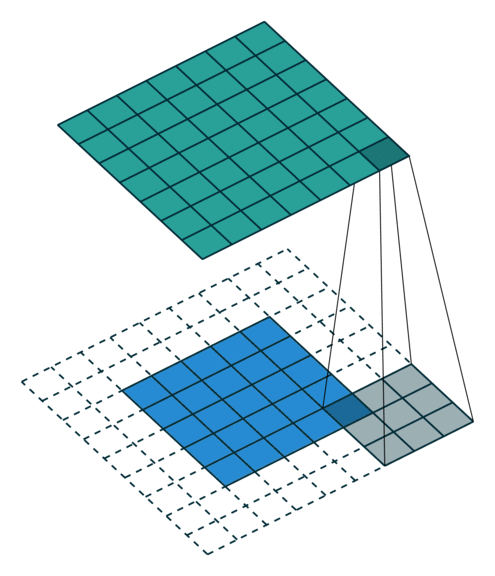
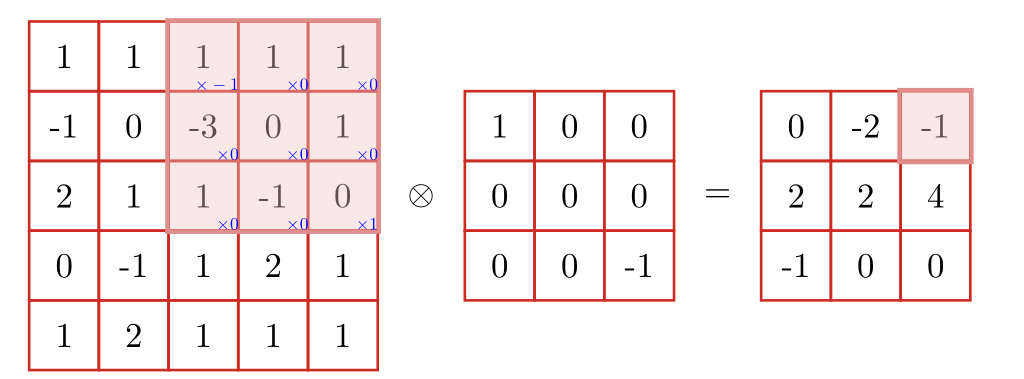


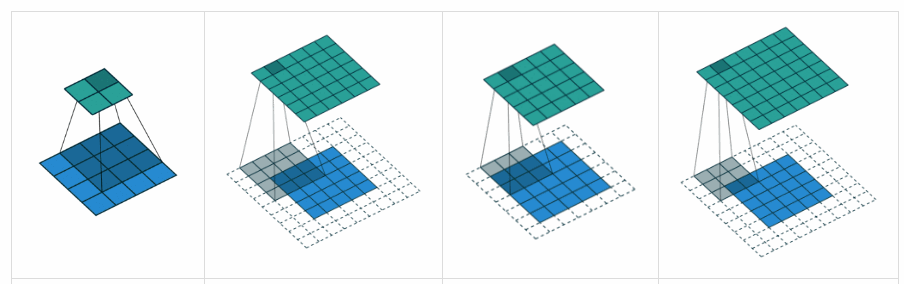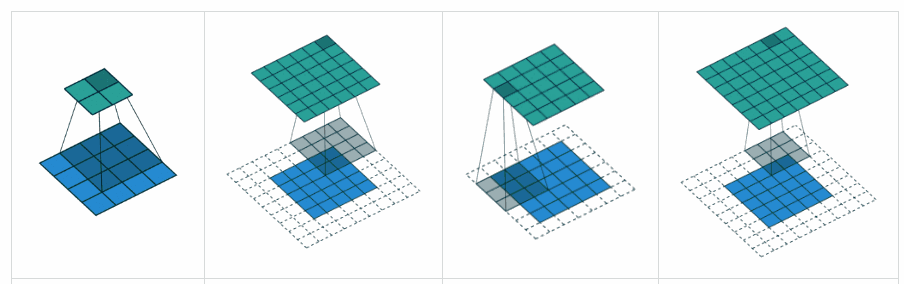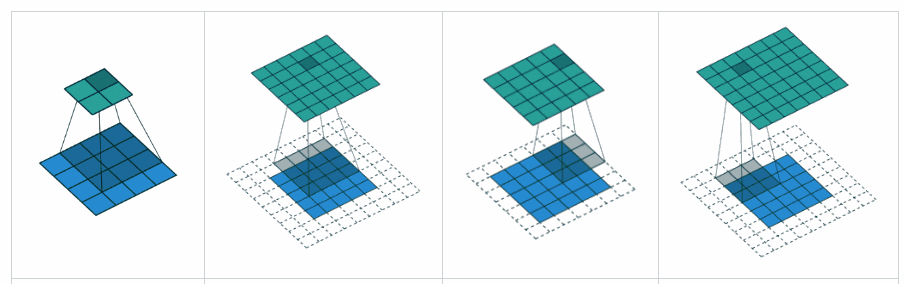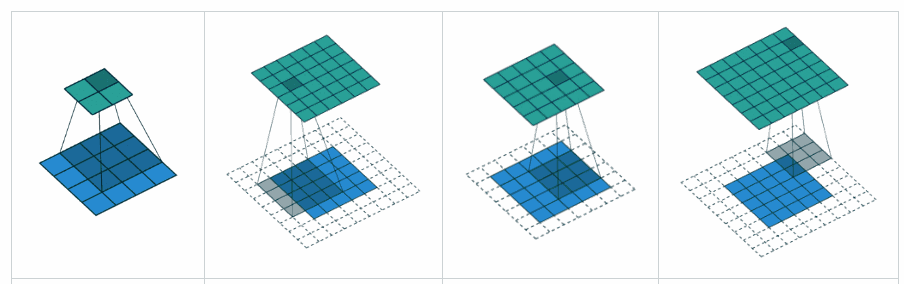
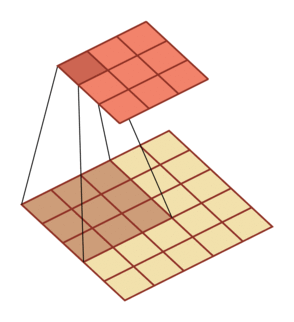
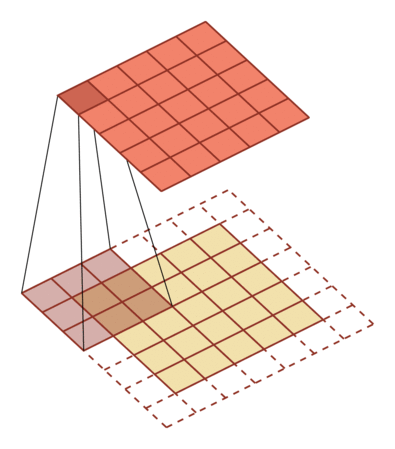
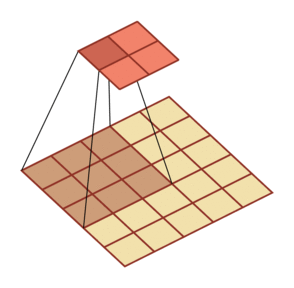
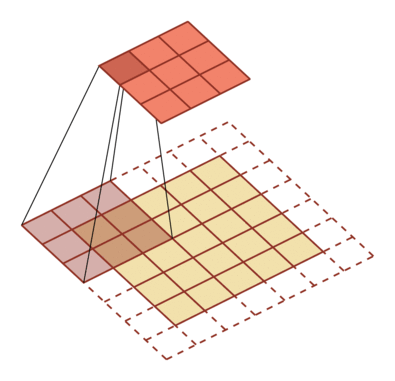
卷积层计算公式¶

用卷积层替换全连接层
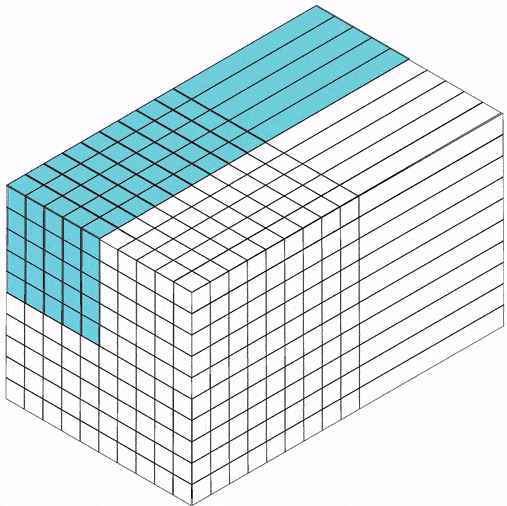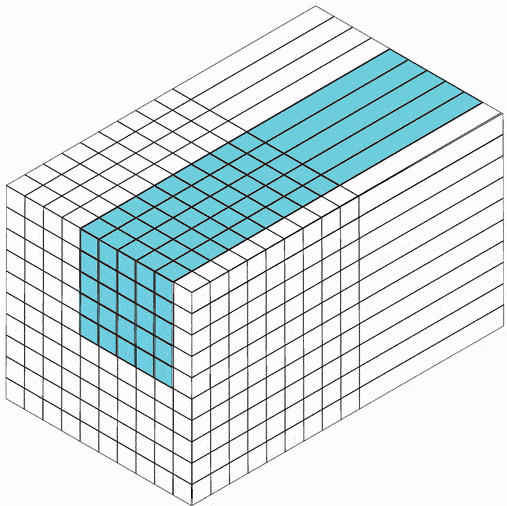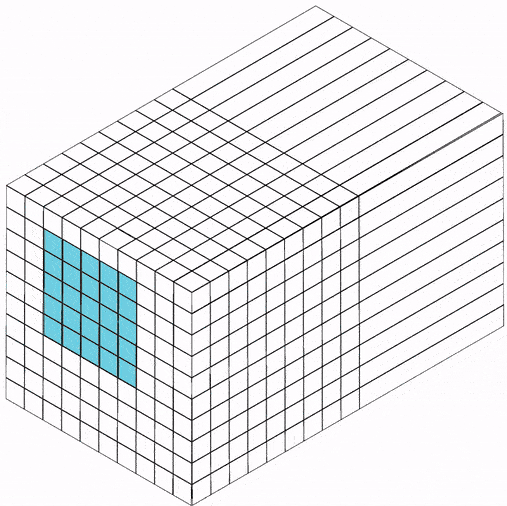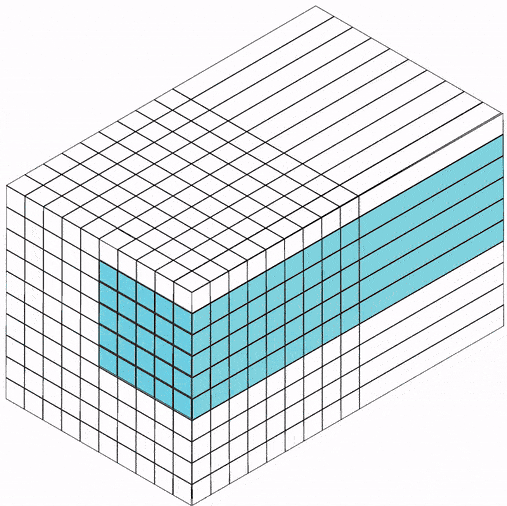
在全连接前馈神经网络中,如果第 层有 个神经元,第 层有 个神经元。连接边有 条,即权重矩阵有 个参数。当 和 都很大时,权重矩阵参数量巨大,训练会很慢。
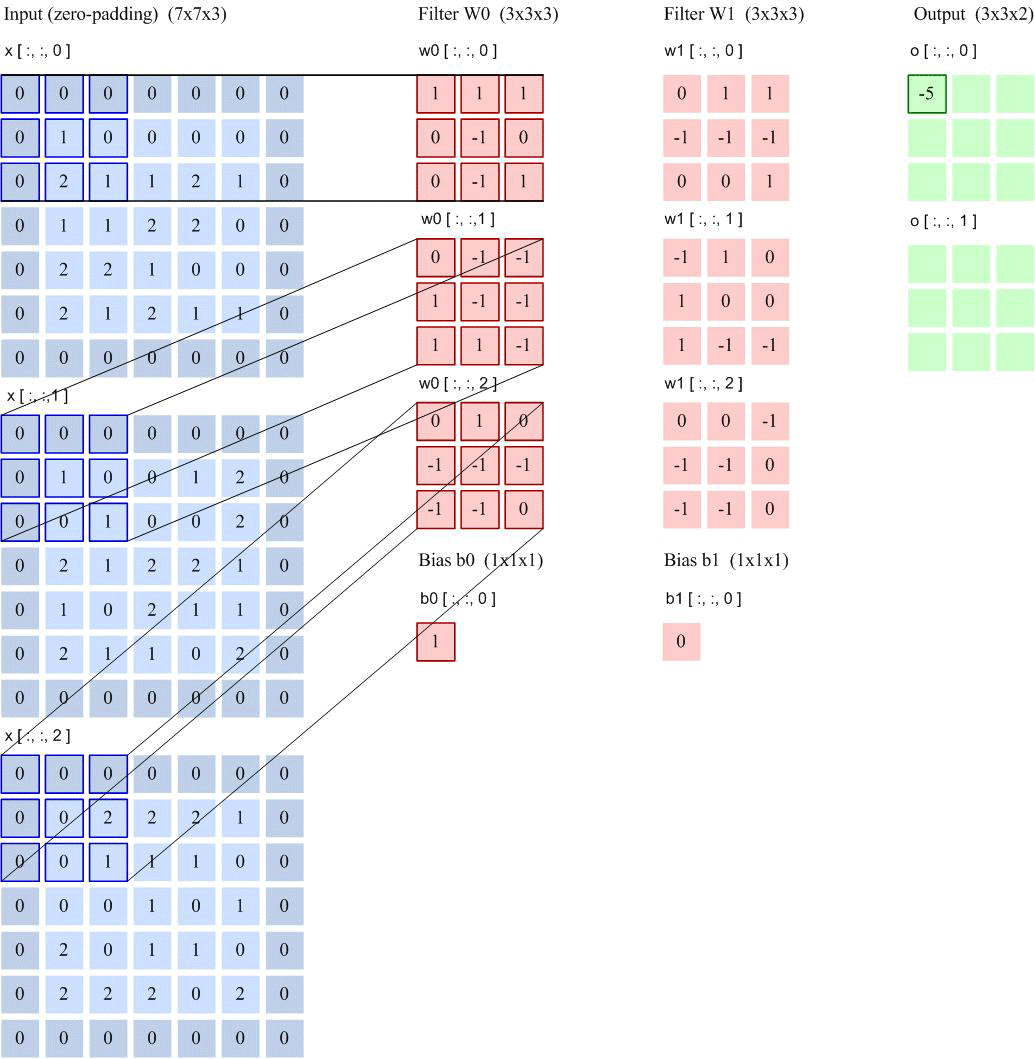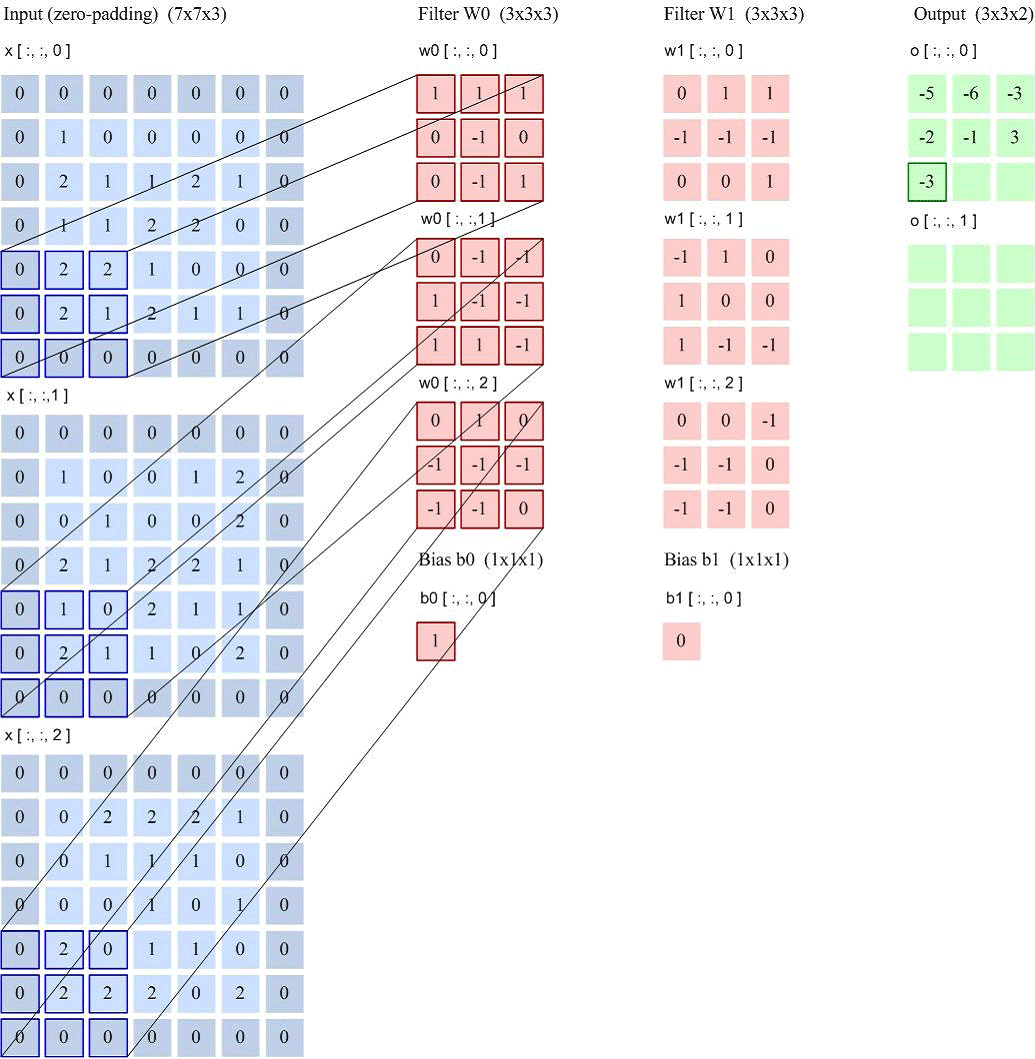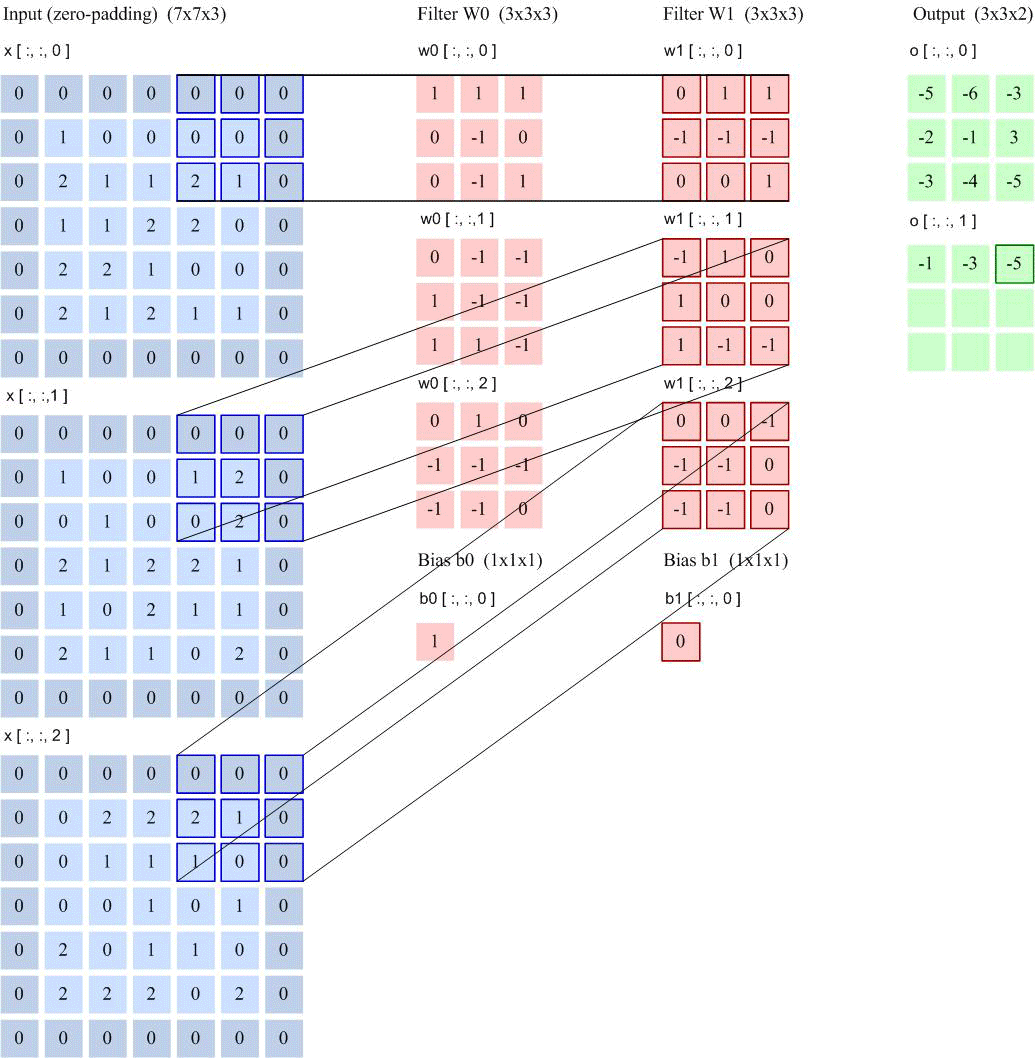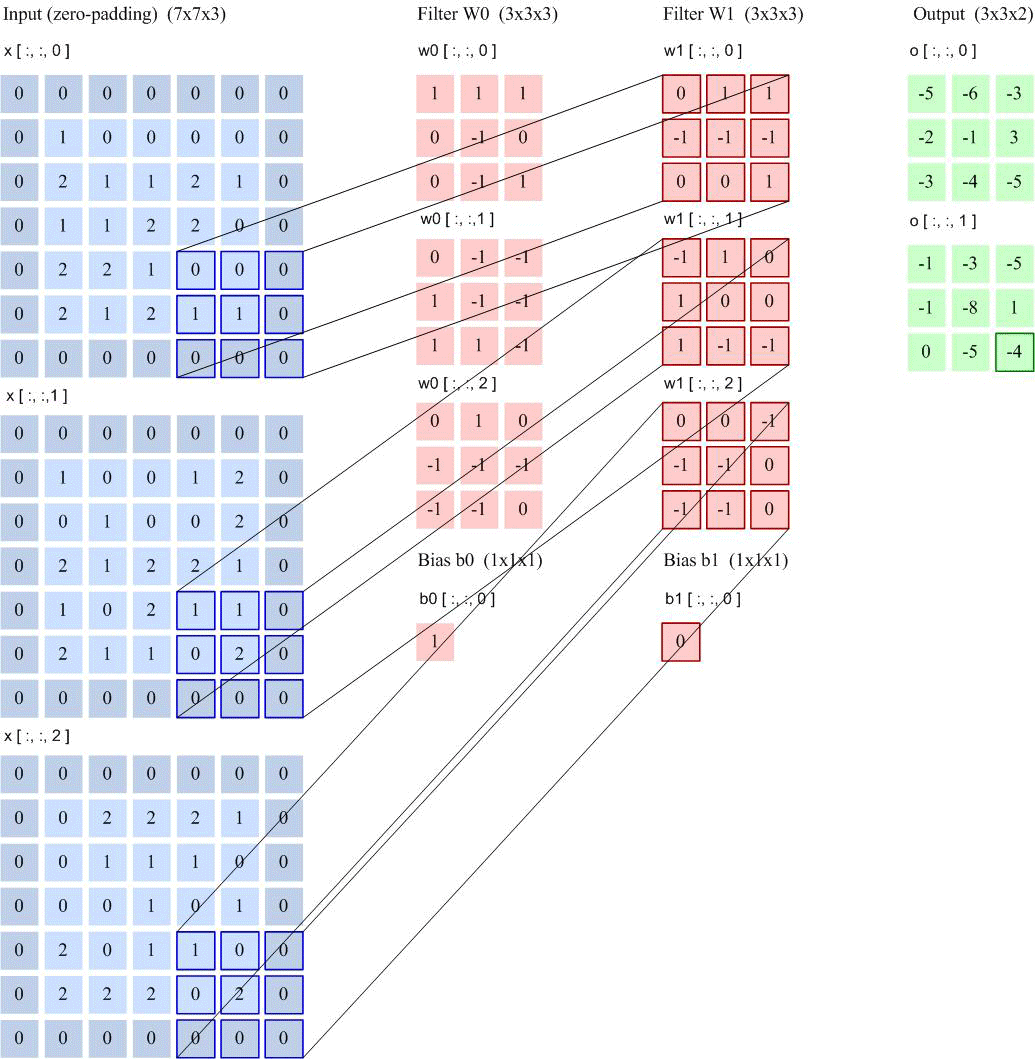
如果用卷积代替全连接,第 层的净输入 是第 层的激活值 与卷积核 的卷积:
其中卷积核 是可学习的权重向量, 是可学习的偏置。
由于局部连接和权重共享,卷积层的参数只有一个 维权重 和一个1维偏置 ,共 个参数。参数数量与神经元数量无关。此外,第 层的神经元数量不是任意选择的,而是满足 。
卷积核作为可训练的特征提取器¶

特征图(Feature Map)是通过卷积提取的图像(或其他特征图),每个特征图都可以作为一类提取的图像特征。为了提高卷积网络的表达能力,每层可以使用多个不同的特征图,以更好地表示图像的特征。

卷积核可以被视为特征提取器。







卷积层参数目录¶


Conv2d 参数参考¶
2d卷积通常由PyTorch nn.Conv2d类实现:
nn.Conv2d(in_channels, out_channels, kernel_size, stride = 1, padding = 0, dilation = 1, groups = 1, bias = True)对于二维卷积层,输入 和输出 的计算如下:
表示二维互相关, 是批量大小, 是通道数,, 表示输入图像的宽度和高度像素。
in_channels (int): 输入信号的通道数。
out_channels (int): 卷积产生的通道数。
kerner_size (int or tuple): 卷积核的大小。
stride(int or tuple, optional ): 卷积步长,默认为 1。
padding(int or tuple, optional ): 添加到输入每个边缘的层数。
dilation(int or tuple,optional ): 卷积核元素之间的间距。
groups( int, optional ): 从输入通道到输出通道的阻塞连接数。默认值:1
bias(bool, optional): 如果 bias=True,添加偏置。
输出形状。
输入:
输出:
参数 kernel_size, stride, padding, 和 dilation 也可以是一个 int 数据。此时,卷积高度和宽度具有相同的值;它也可以是一个元组数组。元组的第一个维度表示高度值,第二个维度表示宽度值
训练一个简单的一维卷积示例¶
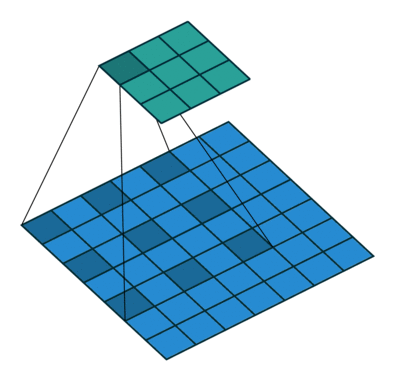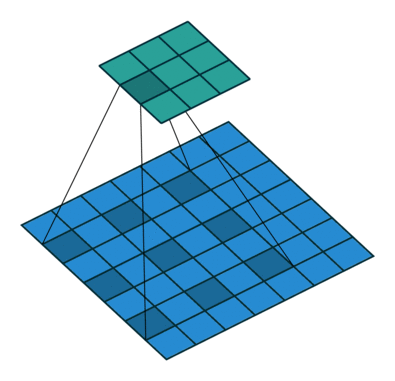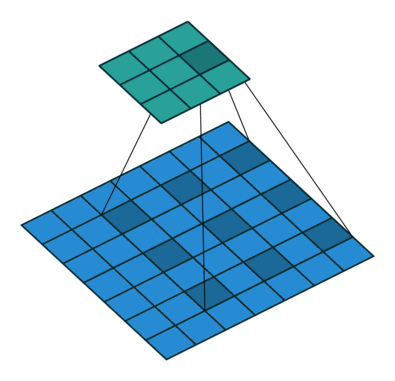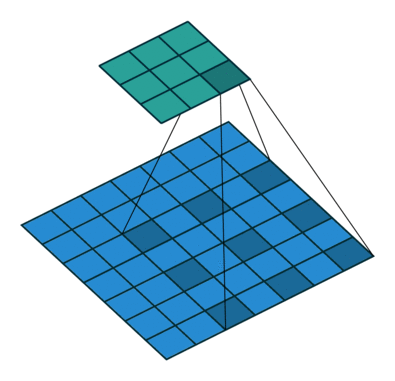
卷积核元素之间的间距:dilation = {2,2}
卷积层参数:
weight(tensor)-卷积的权重,大小为 (out_channels , in_channels, kernel_size)
bias(tensor)-卷积的偏置系数,大小为 (out_channel)
一维卷积示例输出¶
作为一个训练一维卷积层的例子
import torch
from torch import nn
import torch.nn.functional as F
# 这个二维卷积层使用4D输入和4D输出格式
# (batch_size, channel, height, width),其中批量大小和通道数
# 均为 1
X = torch.ones((6, 8))
X[:, 2:6] = 0
X.unsqueeze_(0).unsqueeze_(0) # X.shape [1,1,6,8]
K = torch.tensor([[[[1.0, -1.0]]]]) # K.shape [1,1,1,2]
Y = F.conv2d(X, K) # Y.shape [1,1,6,7]
# 使用Conv2d构建一个具有1个输出通道的一维卷积层
# 卷积核形状为 (1, 2)
conv2d = nn.Conv2d(1, 1, kernel_size=(1, 2), bias=False)
lr = 3e-2 # 学习率
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
conv2d.zero_grad()
l.sum().backward()
# 使用梯度更新权重
conv2d.weight.data[:] -= lr * conv2d.weight.grad
if (i + 1) % 2 == 0:
print(f'epoch {i+1}, loss {l.sum():.3f}')
print("convolution weights =", conv2d.weight.data.reshape((1, 2)))epoch 2, loss 3.674
epoch 4, loss 0.915
epoch 6, loss 0.276
epoch 8, loss 0.096
epoch 10, loss 0.037
convolution weights = tensor([[ 1.0111, -0.9726]])



平均池化机制¶
池化层(也称为子采样层),其功能是进行特征选择,减少特征数量,从而减少参数数量。
虽然卷积层可以显着减少网络中的连接数量,但特征图体积中的神经元数量并没有显着减少。如果后面连接分类器,分类器的输入维度仍然很高,容易过拟合。为了解决这个问题,可以在卷积层之后添加池化层来降低特征维度并避免过拟合。
有两种常用的聚合函数:
最大池化:对于一个区域,选择该区域中所有神经元的最大活动值作为该区域的表示。
平均池化:一般取该区域内所有神经元活动值的平均值。




从传统流程到深度特征¶


CNN学习到的层次语义¶


从浅层学习到的特征是简单的边缘、角、纹理、几何形状、表面等。
从深层学习到的特征更加复杂和抽象,例如狗、人脸、键盘等。

CNN以图像的原始像素作为输入,根据输出层定义的损失函数使用反向传播算法进行端到端学习,从而自动学习从图像低级到高级的分层语义表达。

用深度换取宽滤波器¶
为什么选择“深”网络结构而不是“宽”网络结构?
即使只有一个隐藏层,只要有足够的神经元,神经网络理论上可以拟合任何连续函数。为什么要使用深层网络结构?
深度网络可以从局部到全局“理解图像”
在学习复杂特征(如人脸识别)时,浅层卷积层感受野小,学习局部特征,而深层卷积层感受野大,学习整体特征。
深度网络减少了权重数量
用深度换宽度,用多个小卷积代替一个大卷积,在获得更多样化特征的同时需要更少的权重。


CIFAR10 数据集图像分类¶
# CIFAR10 数据集图像分类
import time
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
import matplotlib.pyplot as plt
# 配置中文字体支持
plt.rcParams['font.sans-serif'] = [
'Noto Sans CJK SC', 'Noto Sans CJK JP', 'SimHei',
'Microsoft YaHei', 'WenQuanYi Micro Hei', 'DejaVu Sans'
]
plt.rcParams['axes.unicode_minus'] = False
# 超参数
RANDOM_SEED = 1
LEARNING_RATE = 0.01
BATCH_SIZE = 128
NUM_EPOCHS = 10
# 网络参数
NUM_FEATURES = 32 * 32
NUM_CLASSES = 10
# 其他
DEVICE = torch.device("cuda:0")
torch.manual_seed(0)
# 加载数据集,transforms.ToTensor() 将数据归一化为 [0.0,1.0]
train_dataset = datasets.CIFAR10(root='../../../dataset/cifar10', train=True, transform=transforms.ToTensor(),download=True)
test_dataset = datasets.CIFAR10(root='../../../dataset/cifar10', train=False, transform=transforms.ToTensor())
train_loader = DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=BATCH_SIZE,
shuffle=False)
for images, labels in train_loader: # 验证数据
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
break
Image batch dimensions: torch.Size([128, 3, 32, 32])
Image label dimensions: torch.Size([128])
简单卷积神经网络¶
输出大小计算¶
对于卷积层和池化层,输出空间维度可以使用以下公式计算:
其中:
= 输出大小(高度或宽度)
= 输入大小(高度或宽度)
= 滤波器/核大小
= 填充
= 步长
计算所需输出大小所需的填充:
class ConvNet(torch.nn.Module):
def __init__(self, num_classes, n_channels):
super().__init__()
self.n_channels = n_channels
self.features = nn.Sequential(
nn.Conv2d(in_channels=n_channels, # 32x32x3 => 28x28x18
out_channels=6*n_channels, kernel_size=5,
padding=0), # (1(28-1) - 32 + 5) / 2 = 0
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, # 28x28x18 => 14x14x18
stride=2,
padding=0), # (2(14-1) - 28 + 2) = 0
nn.Conv2d(in_channels=6*n_channels, # 14x14x18 => 14x14x36
out_channels=12*n_channels, kernel_size=5, stride=(1, 1),
padding=2), # (1(14-1) - 14 + 5) / 2 = 2
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), # 14x14x36 => 7x7x36
stride=(2, 2),
padding=0)) # (2(7-1) - 14 + 2) = 0
self.classifier = torch.nn.Linear(7 * 7 * 12 * n_channels, num_classes)
# 可以使用高斯分布初始化权重,但高斯初始化
# 权重很少使用
for m in self.modules():
if isinstance(m, torch.nn.Conv2d) or isinstance(m, torch.nn.Linear):
m.weight.data.normal_(0.0, 0.01)
if m.bias is not None:
m.bias.detach().zero_()
def forward(self, x):
out = self.features(x)
logits = self.classifier(out.view(-1, 7*7*12*self.n_channels))
probas = F.softmax(logits, dim=1)
return logits, probas
def compute_accuracy(model, data_loader, device):
"""计算模型在给定数据加载器上的准确率。"""
model.eval()
correct_pred, num_examples = 0, 0
with torch.no_grad():
for features, targets in data_loader:
features, targets = features.to(device), targets.to(device)
logits, probas = model(features)
_, predicted_labels = torch.max(probas, 1)
num_examples += targets.size(0)
correct_pred += (predicted_labels == targets).sum()
return correct_pred.float() / num_examples * 100
def train_model(model, train_loader, test_loader, num_epochs, learning_rate,
device, log_interval=50, momentum=0.9):
"""
训练神经网络模型。
参数:
model: 要训练的PyTorch模型
train_loader: 训练数据的数据加载器
test_loader: 测试数据的数据加载器
num_epochs: 训练轮数
learning_rate: 优化器的学习率
device: 训练设备 (cuda/cpu)
log_interval: 每 N 个批次打印日志 (默认: 50)
momentum: SGD 优化器的动量 (默认: 0.9)
返回:
训练好的模型
"""
model = model.to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum)
print(model)
total_params = sum(p.numel() for p in model.parameters())
print(f'Total parameters: {total_params:,}')
start_time = time.time()
for epoch in range(num_epochs):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
features, targets = features.to(device), targets.to(device)
# 前向传播
logits, probas = model(features)
loss = F.cross_entropy(logits, targets)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print(f'Epoch: {epoch+1:03d}/{num_epochs:03d} | '
f'Batch {batch_idx:04d}/{len(train_loader):04d} | '
f'Loss: {loss:.4f}')
# 在训练集上评估
train_acc = compute_accuracy(model, train_loader, device)
print(f'Epoch: {epoch+1:03d}/{num_epochs:03d} | Train Accuracy: {train_acc:.3f}%')
print(f'Time elapsed: {(time.time() - start_time)/60:.2f} min')
print(f'Total Training Time: {(time.time() - start_time)/60:.2f} min')
# 最终测试评估
test_acc = compute_accuracy(model, test_loader, device)
print(f'Test Accuracy: {test_acc:.2f}%')
return model
def visualize_prediction(model, test_loader, device, class_names=None):
"""
可视化测试集中的样本预测。
参数:
model: 训练好的模型
test_loader: 测试数据的数据加载器
device: 设备 (cuda/cpu)
class_names: 类别名称列表 (可选)
"""
if class_names is None:
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
# 从测试集中获取一个批次
features, targets = next(iter(test_loader))
# 显示图像
nhwc_img = np.transpose(features[0], axes=(1, 2, 0))
plt.imshow(nhwc_img)
plt.title(f'True label: {class_names[targets[0]]}')
plt.show()
# 进行预测
model.eval()
with torch.no_grad():
logits, probas = model(features.to(device)[0:1])
pred_class = torch.argmax(probas, dim=1).item()
confidence = probas[0][pred_class].item() * 100
print(f'Predicted: {class_names[pred_class]} ({confidence:.2f}%)')
print(f'True label: {class_names[targets[0]]}')
# 在 CIFAR-10 上训练 ConvNet 模型
NUM_CHANNELS = images.shape[1]
torch.manual_seed(RANDOM_SEED)
model = ConvNet(NUM_CLASSES, NUM_CHANNELS)
model = train_model(model, train_loader, test_loader,
num_epochs=NUM_EPOCHS, learning_rate=LEARNING_RATE, device=DEVICE)
visualize_prediction(model, test_loader, DEVICE)
ConvNet(
(features): Sequential(
(0): Conv2d(3, 18, kernel_size=(5, 5), stride=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(18, 36, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU()
(5): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
(classifier): Linear(in_features=1764, out_features=10, bias=True)
)
Total parameters: 35,254
Epoch: 001/010 | Batch 0000/0391 | Loss: 2.3028
Epoch: 001/010 | Batch 0050/0391 | Loss: 2.2983
Epoch: 001/010 | Batch 0100/0391 | Loss: 2.2658
Epoch: 001/010 | Batch 0150/0391 | Loss: 2.1291
Epoch: 001/010 | Batch 0200/0391 | Loss: 2.0341
Epoch: 001/010 | Batch 0250/0391 | Loss: 1.8129
Epoch: 001/010 | Batch 0300/0391 | Loss: 1.8228
Epoch: 001/010 | Batch 0350/0391 | Loss: 1.8767
Epoch: 001/010 | Train Accuracy: 35.654%
Time elapsed: 0.15 min
Epoch: 002/010 | Batch 0000/0391 | Loss: 1.7347
Epoch: 002/010 | Batch 0050/0391 | Loss: 1.7960
Epoch: 002/010 | Batch 0100/0391 | Loss: 1.6602
Epoch: 002/010 | Batch 0150/0391 | Loss: 1.5860
Epoch: 002/010 | Batch 0200/0391 | Loss: 1.5243
Epoch: 002/010 | Batch 0250/0391 | Loss: 1.4931
Epoch: 002/010 | Batch 0300/0391 | Loss: 1.3872
Epoch: 002/010 | Batch 0350/0391 | Loss: 1.4350
Epoch: 002/010 | Train Accuracy: 48.968%
Time elapsed: 0.29 min
Epoch: 003/010 | Batch 0000/0391 | Loss: 1.4485
Epoch: 003/010 | Batch 0050/0391 | Loss: 1.3256
Epoch: 003/010 | Batch 0100/0391 | Loss: 1.3782
Epoch: 003/010 | Batch 0150/0391 | Loss: 1.2879
Epoch: 003/010 | Batch 0200/0391 | Loss: 1.2356
Epoch: 003/010 | Batch 0250/0391 | Loss: 1.3483
Epoch: 003/010 | Batch 0300/0391 | Loss: 1.3397
Epoch: 003/010 | Batch 0350/0391 | Loss: 1.4359
Epoch: 003/010 | Train Accuracy: 53.936%
Time elapsed: 0.44 min
Epoch: 004/010 | Batch 0000/0391 | Loss: 1.3501
Epoch: 004/010 | Batch 0050/0391 | Loss: 1.2701
Epoch: 004/010 | Batch 0100/0391 | Loss: 1.0416
Epoch: 004/010 | Batch 0150/0391 | Loss: 1.3438
Epoch: 004/010 | Batch 0200/0391 | Loss: 1.2295
Epoch: 004/010 | Batch 0250/0391 | Loss: 1.2022
Epoch: 004/010 | Batch 0300/0391 | Loss: 1.0842
Epoch: 004/010 | Batch 0350/0391 | Loss: 1.2392
Epoch: 004/010 | Train Accuracy: 58.422%
Time elapsed: 0.58 min
Epoch: 005/010 | Batch 0000/0391 | Loss: 1.0545
Epoch: 005/010 | Batch 0050/0391 | Loss: 1.0499
Epoch: 005/010 | Batch 0100/0391 | Loss: 1.1314
Epoch: 005/010 | Batch 0150/0391 | Loss: 1.0079
Epoch: 005/010 | Batch 0200/0391 | Loss: 1.1037
Epoch: 005/010 | Batch 0250/0391 | Loss: 1.1274
Epoch: 005/010 | Batch 0300/0391 | Loss: 1.2209
Epoch: 005/010 | Batch 0350/0391 | Loss: 1.2172
Epoch: 005/010 | Train Accuracy: 62.880%
Time elapsed: 0.72 min
Epoch: 006/010 | Batch 0000/0391 | Loss: 1.1698
Epoch: 006/010 | Batch 0050/0391 | Loss: 1.0293
Epoch: 006/010 | Batch 0100/0391 | Loss: 1.1239
Epoch: 006/010 | Batch 0150/0391 | Loss: 0.9710
Epoch: 006/010 | Batch 0200/0391 | Loss: 1.0659
Epoch: 006/010 | Batch 0250/0391 | Loss: 1.1221
Epoch: 006/010 | Batch 0300/0391 | Loss: 1.0132
Epoch: 006/010 | Batch 0350/0391 | Loss: 1.0639
Epoch: 006/010 | Train Accuracy: 64.682%
Time elapsed: 0.86 min
Epoch: 007/010 | Batch 0000/0391 | Loss: 0.9687
Epoch: 007/010 | Batch 0050/0391 | Loss: 1.1089
Epoch: 007/010 | Batch 0100/0391 | Loss: 1.0171
Epoch: 007/010 | Batch 0150/0391 | Loss: 1.1129
Epoch: 007/010 | Batch 0200/0391 | Loss: 0.8508
Epoch: 007/010 | Batch 0250/0391 | Loss: 0.8968
Epoch: 007/010 | Batch 0300/0391 | Loss: 1.0293
Epoch: 007/010 | Batch 0350/0391 | Loss: 0.9140
Epoch: 007/010 | Train Accuracy: 65.298%
Time elapsed: 1.00 min
Epoch: 008/010 | Batch 0000/0391 | Loss: 0.9988
Epoch: 008/010 | Batch 0050/0391 | Loss: 0.9248
Epoch: 008/010 | Batch 0100/0391 | Loss: 0.8441
Epoch: 008/010 | Batch 0150/0391 | Loss: 0.9147
Epoch: 008/010 | Batch 0200/0391 | Loss: 0.7417
Epoch: 008/010 | Batch 0250/0391 | Loss: 1.2090
Epoch: 008/010 | Batch 0300/0391 | Loss: 0.9760
Epoch: 008/010 | Batch 0350/0391 | Loss: 1.1017
Epoch: 008/010 | Train Accuracy: 67.432%
Time elapsed: 1.14 min
Epoch: 009/010 | Batch 0000/0391 | Loss: 1.0934
Epoch: 009/010 | Batch 0050/0391 | Loss: 0.9762
Epoch: 009/010 | Batch 0100/0391 | Loss: 0.9169
Epoch: 009/010 | Batch 0150/0391 | Loss: 0.7765
Epoch: 009/010 | Batch 0200/0391 | Loss: 1.1046
Epoch: 009/010 | Batch 0250/0391 | Loss: 0.9554
Epoch: 009/010 | Batch 0300/0391 | Loss: 0.8827
Epoch: 009/010 | Batch 0350/0391 | Loss: 1.0681
Epoch: 009/010 | Train Accuracy: 70.816%
Time elapsed: 1.29 min
Epoch: 010/010 | Batch 0000/0391 | Loss: 0.9479
Epoch: 010/010 | Batch 0050/0391 | Loss: 0.7193
Epoch: 010/010 | Batch 0100/0391 | Loss: 0.7802
Epoch: 010/010 | Batch 0150/0391 | Loss: 0.9593
Epoch: 010/010 | Batch 0200/0391 | Loss: 0.8728
Epoch: 010/010 | Batch 0250/0391 | Loss: 0.8381
Epoch: 010/010 | Batch 0300/0391 | Loss: 0.8193
Epoch: 010/010 | Batch 0350/0391 | Loss: 0.9839
Epoch: 010/010 | Train Accuracy: 70.888%
Time elapsed: 1.43 min
Total Training Time: 1.43 min
Test Accuracy: 65.66%
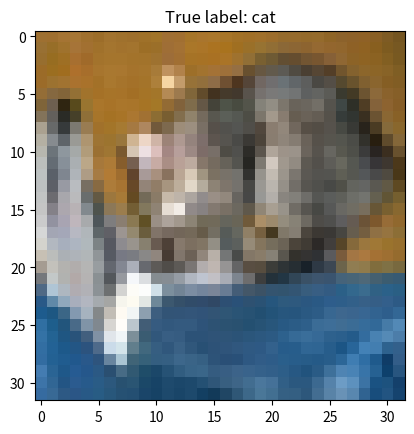
Predicted: cat (46.31%)
True label: cat
有影响力的CNN架构时间线¶
卷积神经网络的演变跨越了二十多年的突破性创新。它始于 LeNet (1998),这是手写数字识别的开创性架构,直到 AlexNet (2012) 以巨大优势赢得 ImageNet 才彻底改变了该领域。这引发了两个平行的研究方向:一个专注于 更深的架构 (VGGNet → ResNet → DenseNet → EfficientNet → ConvNeXt),引入了跳跃连接和神经架构搜索等概念;另一个通过 Network-in-Network 探索 高效模块设计,导致了 Inception 系列 (GoogLeNet, InceptionV3)。同时,移动部署 的需求推动了针对边缘设备优化的轻量级网络 (SqueezeNet, MobileNet, ShuffleNet, Xception) 的发展。在 目标检测 领域,该领域从基于区域的 R-CNN 发展到实时检测器如 YOLO 和 SSD,最终发展到今天高效的 YOLOv8。这条时间线说明了 CNN 研究如何多样化以解决计算机视觉中的准确性、效率和专门任务。
LeNet 第一个卷积神经网络¶
LeNet 是最早提出的卷积神经网络之一,因其在计算机视觉任务中的高效性能而受到广泛关注。该模型由 AT&T 贝尔实验室的研究员 Yann LeCun 于 1989 年提出(并以其命名),用于识别图像中的手写数字。当时,Yann LeCun 发表了第一篇通过反向传播成功训练卷积神经网络的研究,这项工作代表了十多年神经网络研究和发展的顶峰。今天,一些 ATM 机仍运行着 Yann LeCun 和他的同事 Leon Bottou 在 1990 年代编写的代码。
总体而言,LeNet (LeNet-5) 由两部分组成:
卷积编码器:由两个卷积层组成;
全连接层密集块:由三个全连接层组成。

需要多少个卷积滤波器才能得到 16@10x10?
所有卷积层使用 5x5 核,步长为 1。两个池化层都是 2x2 像素,步长为 1。整个网络使用 tanh-sigmoid 激活函数。输出层使用 10 个自定义欧几里得径向基函数神经元作为输出层。输入图像大小为 32x32;

让我们通过 pytorch 实现 LeNet:
为了处理 RGB 彩色图像,滤波器的数量也相应增加了三倍。
我们用 ReLU 激活函数替换 tanh,
欧几里得径向基函数替换为 softmax 函数
class LeNet5(nn.Module):
def __init__(self, num_classes, in_channels=1):
super().__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.features = nn.Sequential(
nn.Conv2d(in_channels, 6*in_channels, kernel_size=5), nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(6*in_channels, 16*in_channels, kernel_size=5), nn.ReLU(),
nn.MaxPool2d(kernel_size=2))
self.classifier = nn.Sequential(
nn.Linear(16*5*5*in_channels, 120*in_channels), nn.ReLU(),
nn.Linear(120*in_channels, 84*in_channels), nn.ReLU(),
nn.Linear(84*in_channels, num_classes))
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
logits = self.classifier(x)
probas = F.softmax(logits, dim=1)
return logits, probas# 在 CIFAR-10 数据集上训练 LeNet5
torch.manual_seed(RANDOM_SEED)
# 创建 LeNet5 模型 (in_channels=3 对应 RGB 图像)
lenet_model = LeNet5(num_classes=NUM_CLASSES, in_channels=3)
# 使用可重用的 train_model 函数训练模型
lenet_model = train_model(
model=lenet_model,
train_loader=train_loader,
test_loader=test_loader,
num_epochs=NUM_EPOCHS,
learning_rate=LEARNING_RATE,
device=DEVICE
)
# 可视化预测
visualize_prediction(lenet_model, test_loader, DEVICE)LeNet5(
(features): Sequential(
(0): Conv2d(3, 18, kernel_size=(5, 5), stride=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(18, 48, kernel_size=(5, 5), stride=(1, 1))
(4): ReLU()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=1200, out_features=360, bias=True)
(1): ReLU()
(2): Linear(in_features=360, out_features=252, bias=True)
(3): ReLU()
(4): Linear(in_features=252, out_features=10, bias=True)
)
)
Total parameters: 548,878
Epoch: 001/010 | Batch 0000/0391 | Loss: 2.3084
Epoch: 001/010 | Batch 0050/0391 | Loss: 2.3033
Epoch: 001/010 | Batch 0100/0391 | Loss: 2.2863
Epoch: 001/010 | Batch 0150/0391 | Loss: 2.1942
Epoch: 001/010 | Batch 0200/0391 | Loss: 2.0822
Epoch: 001/010 | Batch 0250/0391 | Loss: 2.0670
Epoch: 001/010 | Batch 0300/0391 | Loss: 1.9120
Epoch: 001/010 | Batch 0350/0391 | Loss: 1.9094
Epoch: 001/010 | Train Accuracy: 33.042%
Time elapsed: 0.15 min
Epoch: 002/010 | Batch 0000/0391 | Loss: 1.8621
Epoch: 002/010 | Batch 0050/0391 | Loss: 1.9743
Epoch: 002/010 | Batch 0100/0391 | Loss: 1.7709
Epoch: 002/010 | Batch 0150/0391 | Loss: 1.4906
Epoch: 002/010 | Batch 0200/0391 | Loss: 1.5845
Epoch: 002/010 | Batch 0250/0391 | Loss: 1.4732
Epoch: 002/010 | Batch 0300/0391 | Loss: 1.3359
Epoch: 002/010 | Batch 0350/0391 | Loss: 1.5928
Epoch: 002/010 | Train Accuracy: 47.774%
Time elapsed: 0.30 min
Epoch: 003/010 | Batch 0000/0391 | Loss: 1.4677
Epoch: 003/010 | Batch 0050/0391 | Loss: 1.5185
Epoch: 003/010 | Batch 0100/0391 | Loss: 1.4828
Epoch: 003/010 | Batch 0150/0391 | Loss: 1.4581
Epoch: 003/010 | Batch 0200/0391 | Loss: 1.5529
Epoch: 003/010 | Batch 0250/0391 | Loss: 1.5802
Epoch: 003/010 | Batch 0300/0391 | Loss: 1.3445
Epoch: 003/010 | Batch 0350/0391 | Loss: 1.2732
Epoch: 003/010 | Train Accuracy: 53.830%
Time elapsed: 0.45 min
Epoch: 004/010 | Batch 0000/0391 | Loss: 1.2435
Epoch: 004/010 | Batch 0050/0391 | Loss: 1.3382
Epoch: 004/010 | Batch 0100/0391 | Loss: 1.2572
Epoch: 004/010 | Batch 0150/0391 | Loss: 1.2060
Epoch: 004/010 | Batch 0200/0391 | Loss: 1.3661
Epoch: 004/010 | Batch 0250/0391 | Loss: 1.3504
Epoch: 004/010 | Batch 0300/0391 | Loss: 1.4638
Epoch: 004/010 | Batch 0350/0391 | Loss: 1.2385
Epoch: 004/010 | Train Accuracy: 60.138%
Time elapsed: 0.60 min
Epoch: 005/010 | Batch 0000/0391 | Loss: 1.0569
Epoch: 005/010 | Batch 0050/0391 | Loss: 1.1680
Epoch: 005/010 | Batch 0100/0391 | Loss: 1.0282
Epoch: 005/010 | Batch 0150/0391 | Loss: 1.1380
Epoch: 005/010 | Batch 0200/0391 | Loss: 1.1594
Epoch: 005/010 | Batch 0250/0391 | Loss: 1.0428
Epoch: 005/010 | Batch 0300/0391 | Loss: 1.1705
Epoch: 005/010 | Batch 0350/0391 | Loss: 0.9793
Epoch: 005/010 | Train Accuracy: 61.106%
Time elapsed: 0.75 min
Epoch: 006/010 | Batch 0000/0391 | Loss: 1.0712
Epoch: 006/010 | Batch 0050/0391 | Loss: 1.2001
Epoch: 006/010 | Batch 0100/0391 | Loss: 1.1201
Epoch: 006/010 | Batch 0150/0391 | Loss: 1.0208
Epoch: 006/010 | Batch 0200/0391 | Loss: 1.1253
Epoch: 006/010 | Batch 0250/0391 | Loss: 0.8537
Epoch: 006/010 | Batch 0300/0391 | Loss: 1.1534
Epoch: 006/010 | Batch 0350/0391 | Loss: 1.1432
Epoch: 006/010 | Train Accuracy: 66.554%
Time elapsed: 0.90 min
Epoch: 007/010 | Batch 0000/0391 | Loss: 0.9949
Epoch: 007/010 | Batch 0050/0391 | Loss: 0.9254
Epoch: 007/010 | Batch 0100/0391 | Loss: 1.0493
Epoch: 007/010 | Batch 0150/0391 | Loss: 0.8748
Epoch: 007/010 | Batch 0200/0391 | Loss: 0.9781
Epoch: 007/010 | Batch 0250/0391 | Loss: 0.8696
Epoch: 007/010 | Batch 0300/0391 | Loss: 1.0050
Epoch: 007/010 | Batch 0350/0391 | Loss: 1.0733
Epoch: 007/010 | Train Accuracy: 69.488%
Time elapsed: 1.05 min
Epoch: 008/010 | Batch 0000/0391 | Loss: 0.9722
Epoch: 008/010 | Batch 0050/0391 | Loss: 0.9535
Epoch: 008/010 | Batch 0100/0391 | Loss: 0.7756
Epoch: 008/010 | Batch 0150/0391 | Loss: 0.8329
Epoch: 008/010 | Batch 0200/0391 | Loss: 0.7250
Epoch: 008/010 | Batch 0250/0391 | Loss: 0.9765
Epoch: 008/010 | Batch 0300/0391 | Loss: 0.7758
Epoch: 008/010 | Batch 0350/0391 | Loss: 0.8404
Epoch: 008/010 | Train Accuracy: 72.756%
Time elapsed: 1.20 min
Epoch: 009/010 | Batch 0000/0391 | Loss: 0.8349
Epoch: 009/010 | Batch 0050/0391 | Loss: 0.7118
Epoch: 009/010 | Batch 0100/0391 | Loss: 0.7967
Epoch: 009/010 | Batch 0150/0391 | Loss: 0.8754
Epoch: 009/010 | Batch 0200/0391 | Loss: 0.7979
Epoch: 009/010 | Batch 0250/0391 | Loss: 0.7490
Epoch: 009/010 | Batch 0300/0391 | Loss: 0.8563
Epoch: 009/010 | Batch 0350/0391 | Loss: 0.7454
Epoch: 009/010 | Train Accuracy: 75.834%
Time elapsed: 1.35 min
Epoch: 010/010 | Batch 0000/0391 | Loss: 0.7218
Epoch: 010/010 | Batch 0050/0391 | Loss: 0.6687
Epoch: 010/010 | Batch 0100/0391 | Loss: 0.8018
Epoch: 010/010 | Batch 0150/0391 | Loss: 0.7148
Epoch: 010/010 | Batch 0200/0391 | Loss: 0.5839
Epoch: 010/010 | Batch 0250/0391 | Loss: 0.8138
Epoch: 010/010 | Batch 0300/0391 | Loss: 0.5694
Epoch: 010/010 | Batch 0350/0391 | Loss: 0.7357
Epoch: 010/010 | Train Accuracy: 79.008%
Time elapsed: 1.50 min
Total Training Time: 1.50 min
Test Accuracy: 67.82%
Predicted: cat (56.16%)
True label: cat
AlexNet 在 ImageNet 大规模视觉识别挑战赛中的创新与成就¶

AlexNet (2012 ILSVRC 冠军)
AlexNet 以绝对优势(领先第二名 10.9 个百分点)赢得了 2012 年 ImageNet 竞赛。
第一个现代深度卷积网络模型,首次使用了深度卷积网络的相关技术:
例如,使用 GPU 进行并行训练,使用 ReLU 作为非线性激活函数,使用 Dropout 防止过拟合,以及使用数据增强
AlexNet 由八层组成:
五个卷积层,
两个全连接隐藏层
一个全连接输出层。


AlexNet vs LeNet
在 AlexNet 的第一层,卷积窗口形状为 11×11。由于 ImageNet 中的图像比 CIFAR10 图像高宽十倍,因此需要更大的卷积窗口来捕获物体。
第二层的卷积窗口形状减小到 5×5,然后是 3×3。此外,在第一、第二和第五个卷积层之后,网络添加了最大池化层,窗口形状为 3×3,步长为 2。此外,AlexNet 的卷积通道数是 LeNet 的十倍。
在最后一个卷积层之后,有两个巨大的全连接层,有 4096 个输出。这些层需要近 1GB 的模型参数。由于早期 GPU 内存有限,最初的 AlexNet 使用了双数据流设计,以便两个 GPU 各自负责存储和计算模型的一半。
class AlexNet(nn.Module):
"""
为 224x224 ImageNet 图像设计的原始 AlexNet 架构。
注意:这将不能直接用于 CIFAR-10 (32x32) 图像。
对于较小的图像,请使用 AlexNetCIFAR10。
"""
def __init__(self, num_classes):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes))
def forward(self, x):
x = self.avgpool(self.features(x))
x = x.view(x.size(0), 256 * 6 * 6)
logits = self.classifier(x)
probas = F.softmax(logits, dim=1)
return logits, probas
class AlexNetCIFAR10(nn.Module):
"""
适用于 CIFAR-10 (32x32 图像) 的 AlexNet。
使用较小的核和步长来处理 32x32 输入,同时
保持与原始 AlexNet 相同的架构精神。
"""
def __init__(self, num_classes):
super().__init__()
self.features = nn.Sequential(
# 第一层: 32x32x3 -> 32x32x64 -> 16x16x64
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 第二层: 16x16x64 -> 16x16x192 -> 8x8x192
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 第三层: 8x8x192 -> 8x8x384
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# 第四层: 8x8x384 -> 8x8x256
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# 第五层: 8x8x256 -> 8x8x256 -> 4x4x256
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256 * 4 * 4, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes))
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 4 * 4)
logits = self.classifier(x)
probas = F.softmax(logits, dim=1)
return logits, probas
# 在 CIFAR-10 数据集上训练 AlexNetCIFAR10
# 注意:对于 32x32 图像使用 AlexNetCIFAR10(而不是 AlexNet)
torch.manual_seed(RANDOM_SEED)
# 创建 AlexNetCIFAR10 模型(适用于 32x32 图像)
alexnet_model = AlexNetCIFAR10(num_classes=NUM_CLASSES)
# 使用可重用的 train_model 函数训练模型
alexnet_model = train_model(
model=alexnet_model,
train_loader=train_loader,
test_loader=test_loader,
num_epochs=NUM_EPOCHS,
learning_rate=LEARNING_RATE,
device=DEVICE
)
# 可视化预测
visualize_prediction(alexnet_model, test_loader, DEVICE)AlexNetCIFAR10(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=4096, out_features=4096, bias=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=4096, out_features=4096, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
Total parameters: 35,855,178
Epoch: 001/010 | Batch 0000/0391 | Loss: 2.3029
Epoch: 001/010 | Batch 0050/0391 | Loss: 2.3013
Epoch: 001/010 | Batch 0100/0391 | Loss: 2.3047
Epoch: 001/010 | Batch 0150/0391 | Loss: 2.3045
Epoch: 001/010 | Batch 0200/0391 | Loss: 2.3029
Epoch: 001/010 | Batch 0250/0391 | Loss: 2.3041
Epoch: 001/010 | Batch 0300/0391 | Loss: 2.2980
Epoch: 001/010 | Batch 0350/0391 | Loss: 2.2895
Epoch: 001/010 | Train Accuracy: 16.118%
Time elapsed: 0.16 min
Epoch: 002/010 | Batch 0000/0391 | Loss: 2.2292
Epoch: 002/010 | Batch 0050/0391 | Loss: 2.1778
Epoch: 002/010 | Batch 0100/0391 | Loss: 2.0325
Epoch: 002/010 | Batch 0150/0391 | Loss: 1.9394
Epoch: 002/010 | Batch 0200/0391 | Loss: 1.9428
Epoch: 002/010 | Batch 0250/0391 | Loss: 2.0131
Epoch: 002/010 | Batch 0300/0391 | Loss: 1.9228
Epoch: 002/010 | Batch 0350/0391 | Loss: 1.9512
Epoch: 002/010 | Train Accuracy: 24.086%
Time elapsed: 0.31 min
Epoch: 003/010 | Batch 0000/0391 | Loss: 2.0583
Epoch: 003/010 | Batch 0050/0391 | Loss: 1.8332
Epoch: 003/010 | Batch 0100/0391 | Loss: 1.6720
Epoch: 003/010 | Batch 0150/0391 | Loss: 1.8465
Epoch: 003/010 | Batch 0200/0391 | Loss: 1.8026
Epoch: 003/010 | Batch 0250/0391 | Loss: 1.7137
Epoch: 003/010 | Batch 0300/0391 | Loss: 1.7358
Epoch: 003/010 | Batch 0350/0391 | Loss: 1.6658
Epoch: 003/010 | Train Accuracy: 37.192%
Time elapsed: 0.47 min
Epoch: 004/010 | Batch 0000/0391 | Loss: 1.5331
Epoch: 004/010 | Batch 0050/0391 | Loss: 1.5663
Epoch: 004/010 | Batch 0100/0391 | Loss: 1.4637
Epoch: 004/010 | Batch 0150/0391 | Loss: 1.6104
Epoch: 004/010 | Batch 0200/0391 | Loss: 1.6522
Epoch: 004/010 | Batch 0250/0391 | Loss: 1.5442
Epoch: 004/010 | Batch 0300/0391 | Loss: 1.4714
Epoch: 004/010 | Batch 0350/0391 | Loss: 1.5822
Epoch: 004/010 | Train Accuracy: 49.138%
Time elapsed: 0.63 min
Epoch: 005/010 | Batch 0000/0391 | Loss: 1.4219
Epoch: 005/010 | Batch 0050/0391 | Loss: 1.4379
Epoch: 005/010 | Batch 0100/0391 | Loss: 1.3320
Epoch: 005/010 | Batch 0150/0391 | Loss: 1.3758
Epoch: 005/010 | Batch 0200/0391 | Loss: 1.4962
Epoch: 005/010 | Batch 0250/0391 | Loss: 1.4885
Epoch: 005/010 | Batch 0300/0391 | Loss: 1.4095
Epoch: 005/010 | Batch 0350/0391 | Loss: 1.3668
Epoch: 005/010 | Train Accuracy: 51.760%
Time elapsed: 0.78 min
Epoch: 006/010 | Batch 0000/0391 | Loss: 1.2009
Epoch: 006/010 | Batch 0050/0391 | Loss: 1.3119
Epoch: 006/010 | Batch 0100/0391 | Loss: 1.3074
Epoch: 006/010 | Batch 0150/0391 | Loss: 1.2650
Epoch: 006/010 | Batch 0200/0391 | Loss: 1.3149
Epoch: 006/010 | Batch 0250/0391 | Loss: 1.1994
Epoch: 006/010 | Batch 0300/0391 | Loss: 1.2521
Epoch: 006/010 | Batch 0350/0391 | Loss: 1.1206
Epoch: 006/010 | Train Accuracy: 55.720%
Time elapsed: 0.93 min
Epoch: 007/010 | Batch 0000/0391 | Loss: 1.0914
Epoch: 007/010 | Batch 0050/0391 | Loss: 1.2201
Epoch: 007/010 | Batch 0100/0391 | Loss: 1.1340
Epoch: 007/010 | Batch 0150/0391 | Loss: 1.1216
Epoch: 007/010 | Batch 0200/0391 | Loss: 1.0051
Epoch: 007/010 | Batch 0250/0391 | Loss: 1.2617
Epoch: 007/010 | Batch 0300/0391 | Loss: 1.2212
Epoch: 007/010 | Batch 0350/0391 | Loss: 0.9916
Epoch: 007/010 | Train Accuracy: 64.776%
Time elapsed: 1.08 min
Epoch: 008/010 | Batch 0000/0391 | Loss: 1.0764
Epoch: 008/010 | Batch 0050/0391 | Loss: 1.0483
Epoch: 008/010 | Batch 0100/0391 | Loss: 0.9191
Epoch: 008/010 | Batch 0150/0391 | Loss: 1.0944
Epoch: 008/010 | Batch 0200/0391 | Loss: 0.9097
Epoch: 008/010 | Batch 0250/0391 | Loss: 1.0545
Epoch: 008/010 | Batch 0300/0391 | Loss: 1.0059
Epoch: 008/010 | Batch 0350/0391 | Loss: 0.8635
Epoch: 008/010 | Train Accuracy: 68.910%
Time elapsed: 1.23 min
Epoch: 009/010 | Batch 0000/0391 | Loss: 0.8691
Epoch: 009/010 | Batch 0050/0391 | Loss: 0.9915
Epoch: 009/010 | Batch 0100/0391 | Loss: 0.8493
Epoch: 009/010 | Batch 0150/0391 | Loss: 0.9198
Epoch: 009/010 | Batch 0200/0391 | Loss: 0.7874
Epoch: 009/010 | Batch 0250/0391 | Loss: 0.9033
Epoch: 009/010 | Batch 0300/0391 | Loss: 0.7485
Epoch: 009/010 | Batch 0350/0391 | Loss: 0.8600
Epoch: 009/010 | Train Accuracy: 72.656%
Time elapsed: 1.38 min
Epoch: 010/010 | Batch 0000/0391 | Loss: 0.7494
Epoch: 010/010 | Batch 0050/0391 | Loss: 0.7294
Epoch: 010/010 | Batch 0100/0391 | Loss: 0.9488
Epoch: 010/010 | Batch 0150/0391 | Loss: 0.7830
Epoch: 010/010 | Batch 0200/0391 | Loss: 0.7557
Epoch: 010/010 | Batch 0250/0391 | Loss: 0.6734
Epoch: 010/010 | Batch 0300/0391 | Loss: 0.7471
Epoch: 010/010 | Batch 0350/0391 | Loss: 0.7035
Epoch: 010/010 | Train Accuracy: 75.538%
Time elapsed: 1.54 min
Total Training Time: 1.54 min
Test Accuracy: 72.26%
Predicted: dog (56.18%)
True label: cat
VGG网络的两部分结构¶
VGG网络是AlexNet的加深版本,由牛津大学视觉几何组提出的另一个大幅改进的网络,在2014年ImageNet竞赛中获得定位任务第一名和分类任务第二名,将Top5错误率降低到7.3%。
原始VGG网络有5个卷积块,其中前两个各有一个卷积层,后三个各包含两个卷积层。第一个块有64个输出通道,随后的每个块都将输出通道数加倍,直到达到512。由于该网络使用8个卷积层和3个全连接层,因此常被称为VGG-11。

VGG网络可以分为两部分:第一部分主要由卷积层和池化层组成,第二部分由全连接层组成。
更深的网络结构:网络层数从AlexNet的8层增加到VGG的16和19层。更深的网络意味着更强大的网络能力。
使用更小的3×3卷积核:两个3×3感受野相当于一个5×5,同时参数更少,随后的网络设计基本遵循这一范式。

class VGG11(torch.nn.Module):
def vgg_block(self, num_convs, in_channels, out_channels):
net = [nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1), nn.ReLU(True)]
for i in range(num_convs - 1): # 添加若干卷积层
net.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
net.append(nn.ReLU(True))
net.append(nn.MaxPool2d(2, 2)) # 添加池化层
return nn.Sequential(*net)
def __init__(self, num_classes, n_channels):
super().__init__()
num_convs = (1, 1, 2, 2, 2)
channels = ((n_channels, 64), (64, 128), (128, 256), (256, 512), (512, 512))
net = []
for n, c in zip(num_convs, channels):
in_c, out_c = c[0], c[1]
net.append(self.vgg_block(n, in_c, out_c))
self.features = nn.Sequential(*net)
self.classifier = nn.Sequential(nn.Linear(512, 100), nn.ReLU(True),
nn.Linear(100, num_classes))
for m in self.modules():
if isinstance(m, torch.nn.Conv2d) or isinstance(m, torch.nn.Linear):
nn.init.kaiming_uniform_(m.weight, mode='fan_in', nonlinearity='relu')
if m.bias is not None:
m.bias.detach().zero_()
def forward(self, x):
out = self.features(x)
logits = self.classifier(out.view(x.shape[0], -1))
probas = F.softmax(logits, dim=1)
return logits, probasGoogLeNet与Inception的突破¶

Inception 网络(2014年ILSVRC冠军,层数)
参数:GoogLeNet: 4M VS AlexNet: 60M
错误率:6.7%
Inception网络由堆叠多个Inception模块和少量聚合层形成。
解释1x1卷积¶

单通道的1x1卷积只是将所有元素乘以权重

多通道1x1卷积计算所有元素的加权和。

1x1 卷积用于降低通道的维数。这里,192个通道可以压缩到通道。
这种压缩不会造成任何信息丢失。
1x1卷积用于降低通道的维数。我们可以将10个通道的输出减少到4个通道,“而不丢失任何信息”。

5x5卷积使用1x1卷积来降低通道维度。
不使用1x1卷积:
运算次数:(28X28X32) X (5X5X192) = 1.20422亿次运算
使用1x1卷积:
1 X 1 卷积步骤的运算次数:(28X28X16) X (1X1X192) = 240万次运算
5 X 5 卷积步骤的运算次数:(28X28X32) X (5X5X16) = 1000万次运算
总运算次数 = 1240万次运算
在GoogLeNet中堆叠Inception模块¶

在Inception中,一个卷积层包含多个不同大小的卷积操作,称为Inception模块。
Inception模块同时使用不同大小的卷积核(如 1x1, 3x3, 5x5)和最大池化,并将获得的特征图在深度上进行拼接作为输出特征图。宽度相等。

Inception模块在整个GoogLeNet中叠加出现
Inception v3 中的深度分解策略¶

用多层小卷积核替换大卷积核,以减少计算量和参数。
使用两层卷积替换V1中的卷积
使用连续的nx1和1xn卷积替换nxn卷积。
根据卷积的可分离特性:
5x5卷积分解为两层3x3卷积
3x3卷积分解为1x3卷积和3x1卷积。

用多层小卷积核替换大卷积核,以减少计算量和参数。
使用两层卷积替换v1中的卷积
使用连续的nx1和1xn卷积替换nxn卷积。
class Inception(nn.Module): #定义Inception块
def __init__(self,in_channels,c1,c2,c3,c4):
super().__init__()
self.conv1 = nn.Conv2d(in_channels,c1,kernel_size = 1)
self.conv2 = nn.Sequential(nn.Conv2d(in_channels,c2[0],kernel_size = 1),nn.ReLU(),
nn.Conv2d(c2[0],c2[1],kernel_size=3,padding=1),nn.ReLU())
self.conv3 = nn.Sequential(nn.Conv2d(in_channels,c3[0],kernel_size=1),nn.ReLU(),
nn.Conv2d(c3[0],c3[1],kernel_size=5, padding=2),nn.ReLU())
self.conv4 = nn.Sequential(nn.MaxPool2d(kernel_size=3,stride=1,padding=1),
nn.Conv2d(in_channels,c4,kernel_size = 1),nn.ReLU())
def forward(self,X):
return torch.cat((self.conv1(X),
self.conv2(X),
self.conv3(X),
self.conv4(X)), dim = 1)
#GoogleNet网络
class GoogleNet(nn.Module):
def __init__(self,in_channels,classes):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels,out_channels=64,kernel_size=7,stride=2,padding=3),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(in_channels=64,out_channels=64,kernel_size=1),nn.ReLU(),
nn.Conv2d(in_channels=64,out_channels=192,kernel_size=3,padding=1),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
Inception(192,c1=64,c2=[96,128],c3=[16,32],c4=32),
Inception(256,c1=128,c2=[128,192],c3=[32,96],c4=64),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1),
Inception(480,c1=192,c2=[96,208],c3=[16,48],c4=64),
Inception(512,c1=160,c2=[112,224],c3=[24,64],c4=64),
Inception(512,c1=128,c2=[128,256],c3=[24,64],c4=64),
Inception(512,c1=112,c2=[144,288],c3=[32,64],c4=64),
Inception(528,c1=256,c2=[160,320],c3=[32,128],c4=128),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1),
Inception(832,c1=256,c2=[160,320],c3=[32,128],c4=128),
Inception(832,c1=384,c2=[192,384],c3=[48,128],c4=128),
nn.AvgPool2d(kernel_size=7,stride=1),
nn.Dropout(p=0.4),
nn.Flatten(),
nn.Linear(1024,classes),
nn.Softmax(dim=1)
)
def forward(self,X:torch.tensor):
return self.model(X)
残差网络¶

一般来说,随着网络加深,特征级别会越来越高,网络的表达能力也会大大提高。是否可以通过叠加网络层来获得更好的网络?
当传统神经网络的层数从20层增加到56层时,网络的训练误差和测试误差都显著增加,也就是说,随着深度的增加,网络的性能会显著下降。
残差网络(ResNet)是何恺明在CVPR最佳论文《Deep Residual Learning for Image Recognition》中提出的网络,通过在非线性卷积层上添加快捷连接来提高信息传播的效率。
2015年,深度残差网络可以说横扫了图像领域的各大比赛,并以绝对优势获得了多个冠军。而且,在保证网络准确率的前提下,将网络深度增加到了152层,后来进一步将深度增加到了1000层。
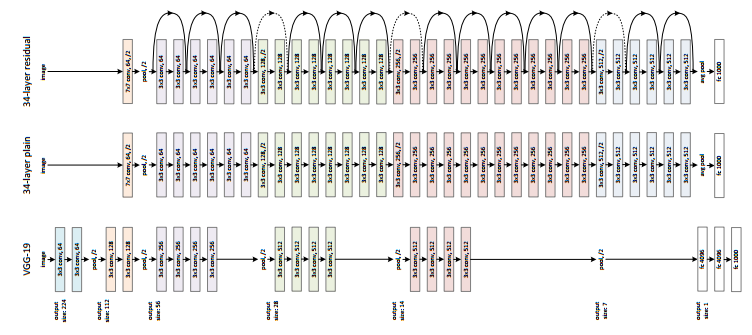
ResNet 2015 ILSVRC 冠军(152层)
错误率:3.57%
残差块的数学解释¶
假设在一个深度网络中,我们期望一个非线性单元(可以是一个或多个卷积层) 来近似一个目标函数 。
目标函数 可以分为两部分:恒等函数 和残差函数
其中,深度网络 用于近似 。
在实践中,残差函数更容易学习,特别是对于深度学习网络。
基本残差块的结构¶

假设原始输入为 ,我们希望学习的固有映射为 。左图直接拟合映射 ,而右图是ResNet的基本架构——残差块用于拟合残差函数 。在残差块中,输入可以通过快捷连接更快地向前传播。当 非常接近恒等函数时,残差函数也很容易捕捉到恒等函数的细微波动。
匹配残差加法的维度¶

ResNet沿用了VGG的3x3卷积层设计。在残差块中,首先是两个卷积层
每个卷积层之后是一个批量归一化层和一个ReLU激活函数。
然后我们通过快捷连接跳过这两个卷积操作,并在最终的ReLU激活函数之前直接添加输入。
这样的设计要求2个卷积层的输出与输入的形状相同,以便它们可以相加。
如果要更改通道数,则需要在求和之前引入一个额外的卷积层将输入转换为所需的形状。
ResNet中的下采样快捷方式
2个卷积层的形状可能与输入形状不同
在快捷连接中将步长设置为大于1,并将1x1卷积的通道数设置为确保加法运算的两个输入具有相同的形状
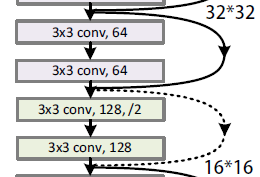
#定义残差块
class ResBlock(nn.Module):
def __init__(self, inchannel, outchannel, stride=1):
super(ResBlock, self).__init__()
#这定义了残差块中两个连续的卷积层
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(outchannel))
self.shortcut = nn.Sequential() #普通的快捷连接
if stride != 1 or inchannel != outchannel:
# 下采样快捷连接,如果形状不同,快捷连接
# 需要使用1x1卷积,将步长设置为大于
# 1用于下采样
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel))
def forward(self, x):
out = self.left(x)
#将两个卷积层的输出与处理后的x相加,以实现
#残差块的基本结构
out = out + self.shortcut(x)
out = F.relu(out)
return out
ResNet-18 网络图¶
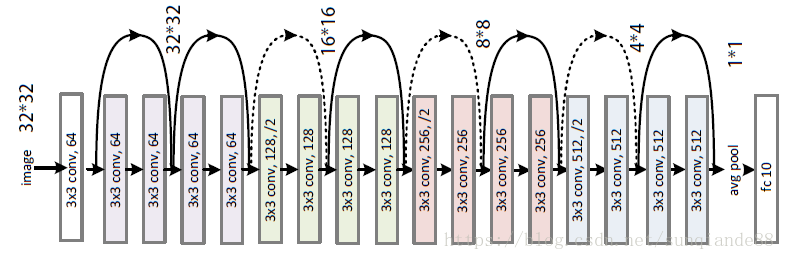
ResNet18的6层结构:
Conv1:第一层卷积,没有快捷机制。
Conv2:第一个残差层,总共有2个残差块。
Conv3:第二个残差层,总共有2个残差块。
Conv4:第三个残差层,总共有2个残差块。
Conv5:第四个残差层,总共有2个残差块。
#定义残差块
class ResNet18(nn.Module):
"""ResNet-18 架构实现"""
def __init__(self, ResBlock, num_classes, in_channels):
super().__init__()
self.inchannel = 64
# 第一个卷积层
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU()
)
# 构建不同通道大小的残差层
res_block_list = self.make_layer(ResBlock, 64, 2, stride=1)
res_block_list += self.make_layer(ResBlock, 128, 2, stride=2)
res_block_list += self.make_layer(ResBlock, 256, 2, stride=2)
res_block_list += self.make_layer(ResBlock, 512, 2, stride=2)
self.res_layers = nn.Sequential(*res_block_list)
# 用于分类的全连接层
self.fc = nn.Linear(512, num_classes)
def make_layer(self, block, channels, num_blocks, stride):
"""残差层的工厂函数"""
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(ResBlock(self.inchannel, channels, stride))
self.inchannel = channels
return layers
def forward(self, x):
# 通过第一个卷积层
out = self.conv1(x)
# 通过残差层
out = self.res_layers(out)
# 全局平均池化
out = F.avg_pool2d(out, 4)
# 为全连接层展平
out = out.view(out.size(0), -1)
# 分类
logits = self.fc(out)
probas = F.softmax(logits, dim=1)
return probas
瓶颈设计节省的参数¶
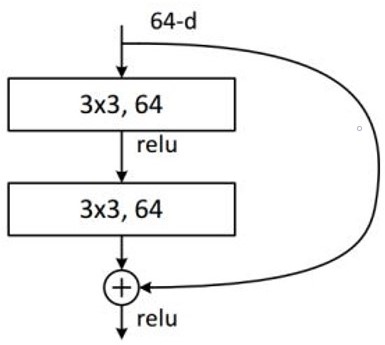
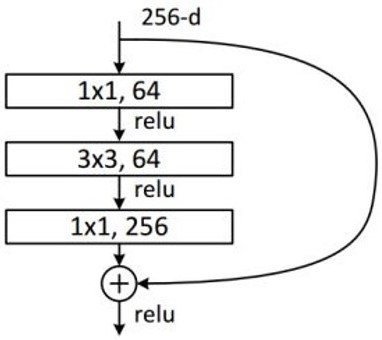
从ResNet50开始,采用瓶颈结构,通过引入1x1卷积降低了计算复杂性:
它增加/减少通道数,以整合跨通道信息,实现多个特征图的线性组合,同时保持原始特征图大小;
与其他大小的卷积核相比,可以大大降低计算复杂性;
如果堆叠两个3x3卷积,只有一个ReLU,但使用1x1卷积时,会有两个ReLU,这引入了更多的非线性映射;
1x1卷积的计算优势:如右图的瓶颈结构,对于具有1x1卷积的256维输入特征,参数数量为1x1x256x64+3x3x64x64+1x1x64x256=69632。对于相同的输入和输出维度,如果我们使用两个3x3卷积,参数数量为(3x3x256x256)x2=1179648。 -根据以上计算,可以看出使用1x1卷积的瓶颈将计算量减少到原来的5.9%。