YOLO 目标检测

前言¶
目标检测作为人工智能领域中图像处理和计算机视觉的经典技术,有着广泛的应用,例如交通监控、图像检索、人脸检测、人机交互等方面都使用了目标检测。目标检测具有巨大的实用价值和应用前景,安防领域的应用最为广泛,比如安全帽、安全带等动态检测,移动侦测、区域入侵检测、物品看护等功能。
什么是目标检测?¶
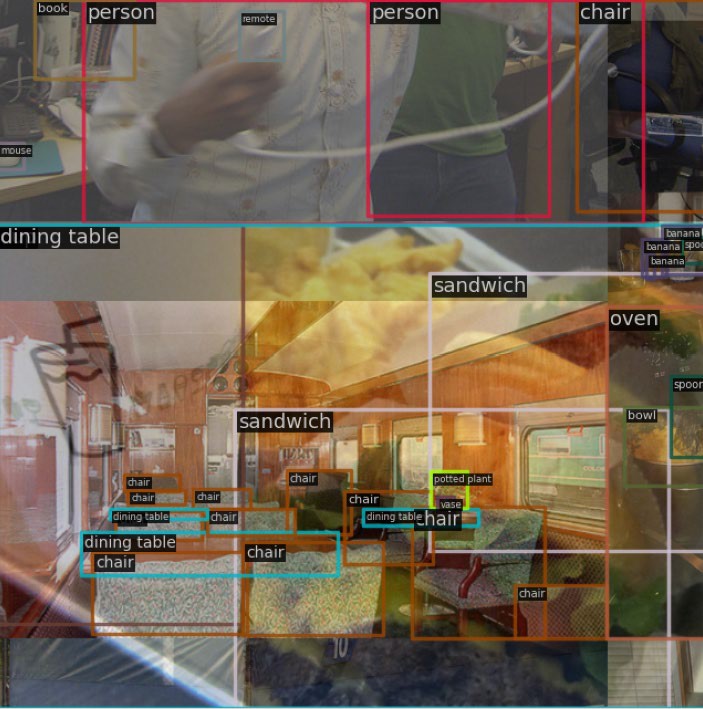
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。
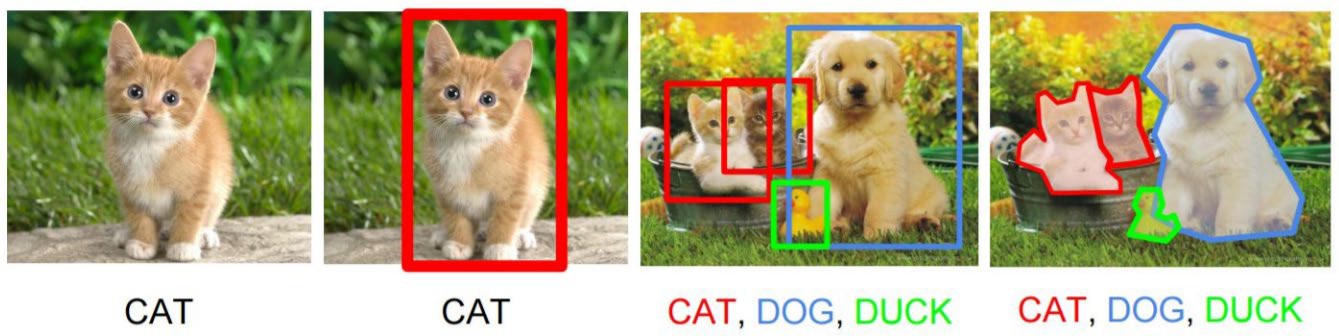
上图展示了计算机视觉任务的层次:
图像分类:识别图像中的单个目标类别
分类+定位:识别类别并给出边界框位置
目标检测:检测多个目标的类别和位置
图像分割:像素级别的目标分割
目标检测方法¶
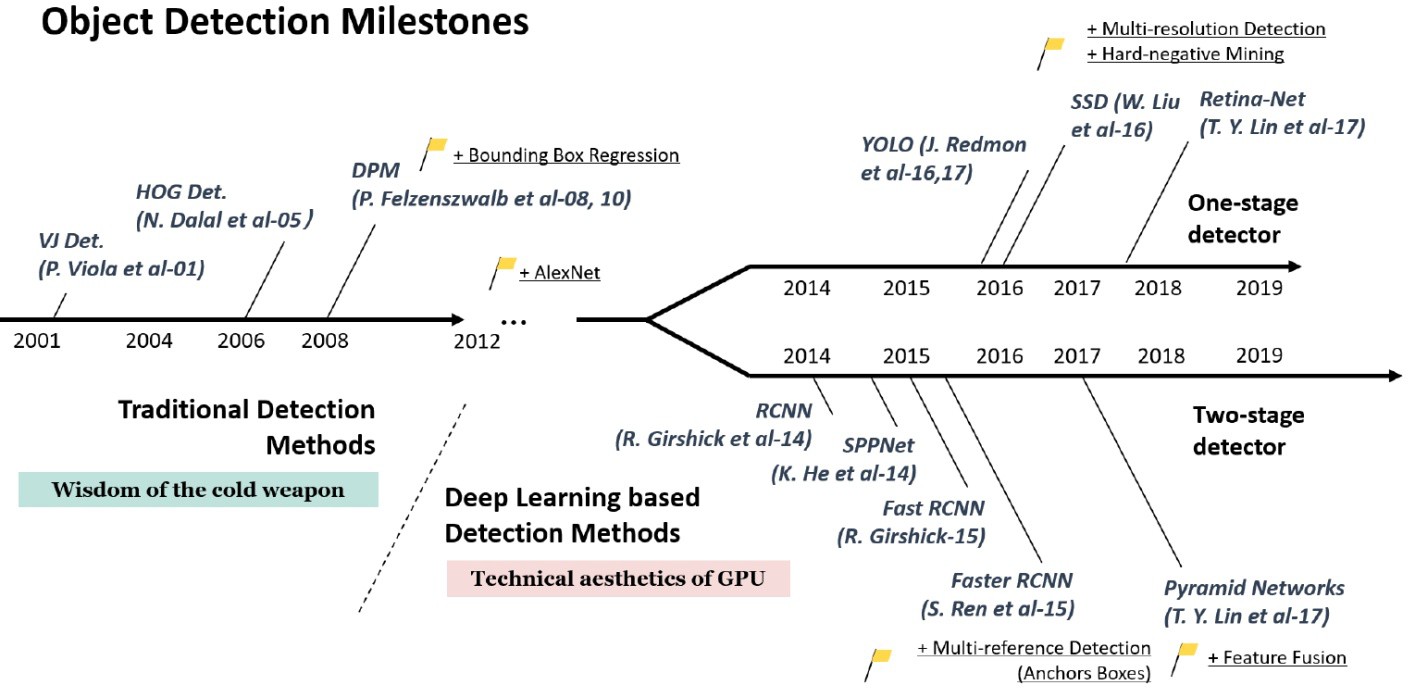
目标检测方法的发展历程可以分为两大类:
两阶段目标检测(Two-stage):
先生成候选区域,再进行分类和回归
代表模型:R-CNN、Fast R-CNN、Faster R-CNN
精度高,但速度较慢
一阶段目标检测(One-stage):

直接在特征图上进行密集预测
代表模型:YOLO、SSD、RetinaNet
速度快,适合实时检测
一阶段目标检测:YOLO¶
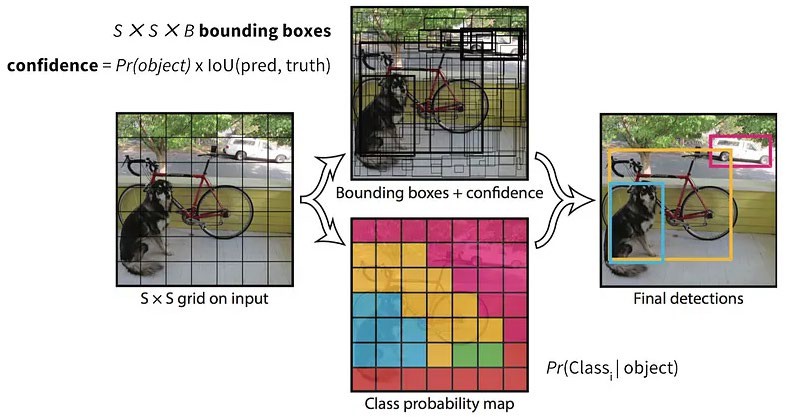
YOLO(You Only Look Once)是一种网格类目标检测算法,是一种单次目标检测器。它把目标检测看作是一个回归问题,将图像分为数个单元格并对每个单元格进行独立地目标检测。
从贝叶斯(Bayesian)视角来看,这一得分计算可以利用概率的链式法则(这也是贝叶斯定理的基础)来解释。 是在对象存在的条件下,该对象属于类别 的**似然(likelihood)或条件概率。 充当网格单元中存在对象的先验(prior)**概率。两者的乘积给出了类别和对象同时存在的联合概率 :
这个联合概率代表了特定类别对象存在于边界框中的置信度。最后,这个置信度被交并比()加权,以反映预测边界框的定位准确度,从而得到最终的得分(Score)。
YOLO的核心思想:
将目标检测视为回归问题,一次前向传播完成检测
端到端训练,速度快
全局推理,能够利用整幅图像的上下文信息
YOLO目标检测流程¶

YOLO的检测流程如下:
网格划分:给定一张输入图像,首先将图像划分成 的网格(YOLOv1中 )
边框预测:对于每个网格,预测 个边框(YOLOv1中 ),每个边框包含:
边框位置:
置信度:
:目标存在于该网格单元中的概率。在训练时,如果某个真实目标(ground truth)的中心点落在该单元格内,则该值为1,否则为0。(注意:在YOLOv1中,即使一个目标跨越了多个网格,也仅有包含该目标中心点的那个网格负责检测该目标。)
:预测边框与真实边框(ground truth)之间的交并比(Intersection over Union)。交并比衡量重叠程度:
类别概率:
:在该单元格存在目标的条件下,该目标属于类别 的条件概率。每个网格单元预测 个类别概率(每个类别一个),这些概率由该单元格内的所有 个边框共享。该概率通过对类别logits进行softmax计算得到:,其中 是网络对类别 的原始输出(logit), 是类别总数。
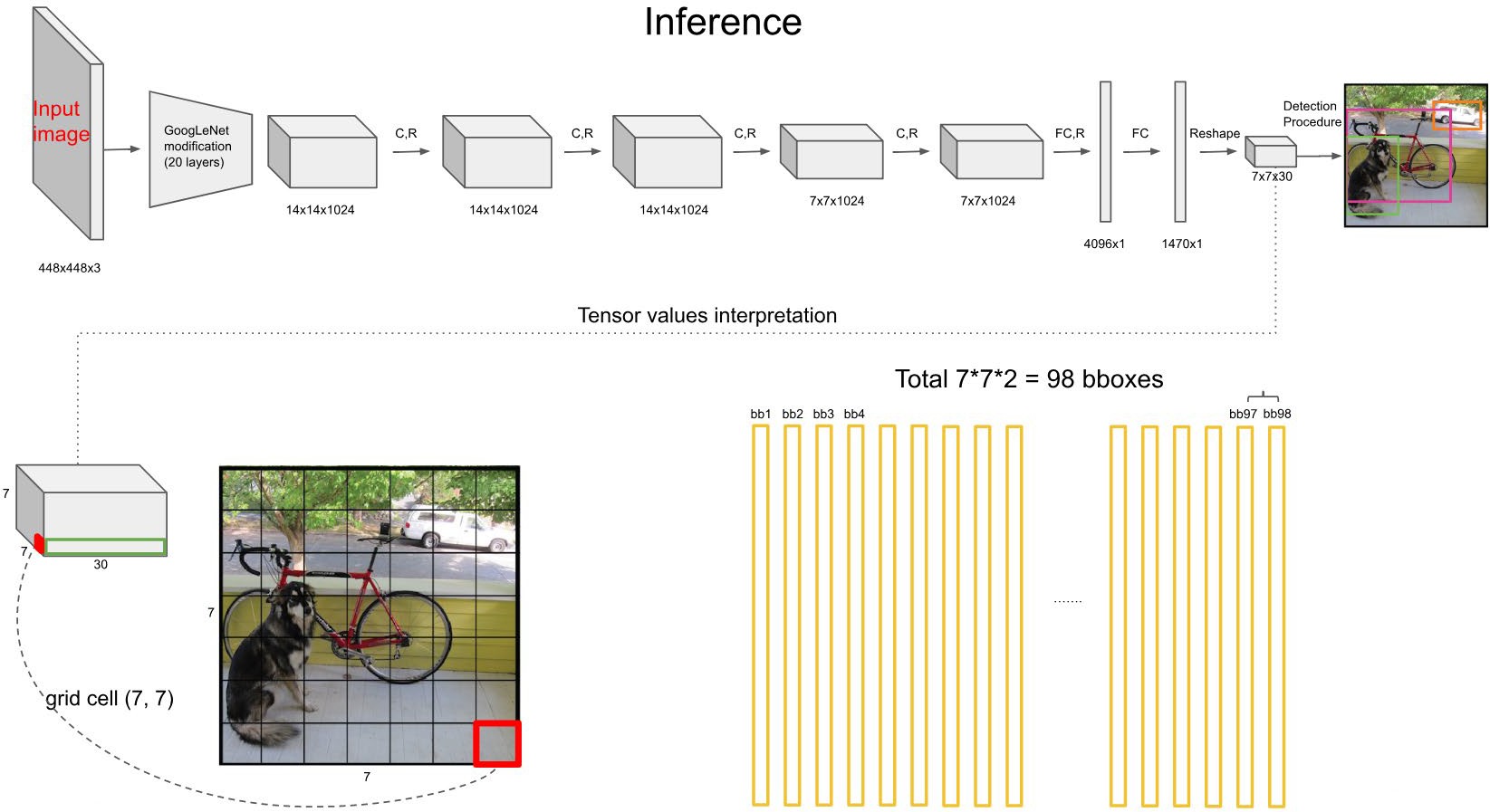
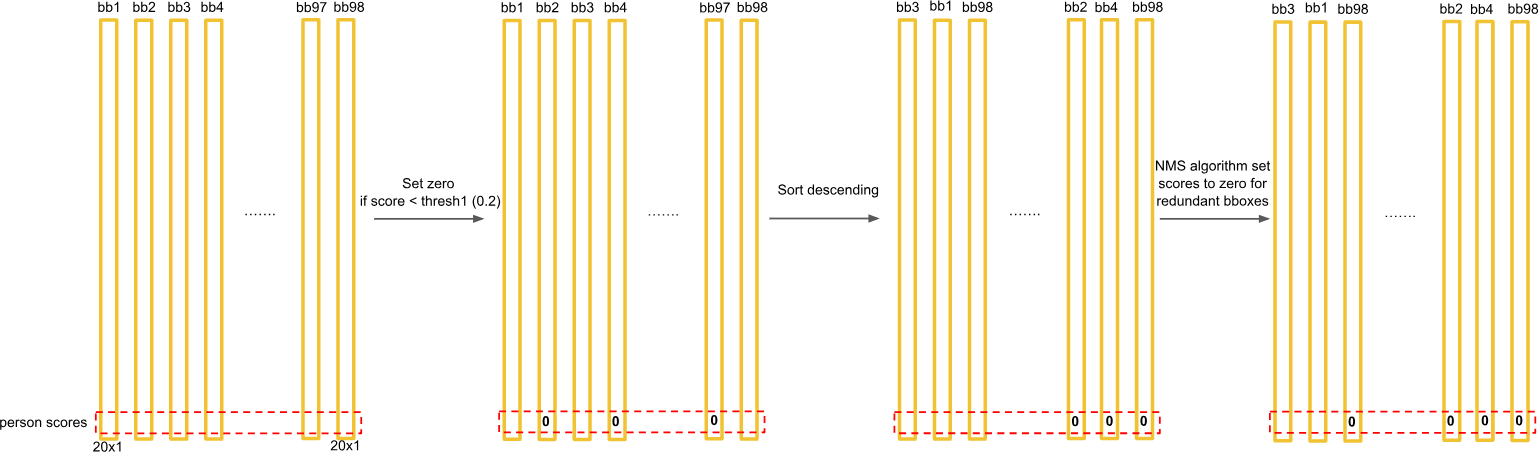
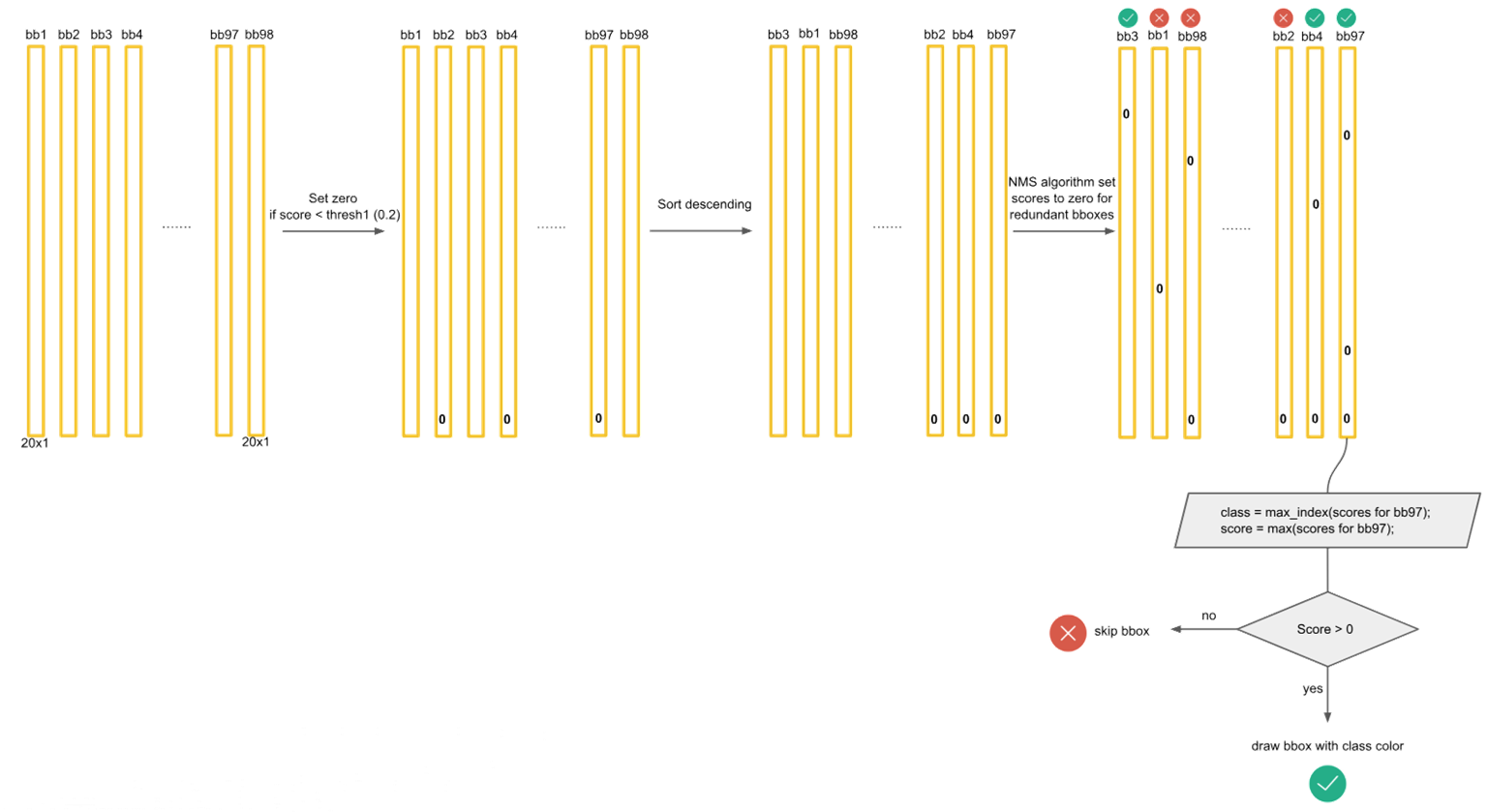
后处理:
根据上一步可以预测出 个目标窗口
根据置信度阈值去除可能性比较低的目标窗口
最后通过NMS(非极大值抑制)去除冗余窗口
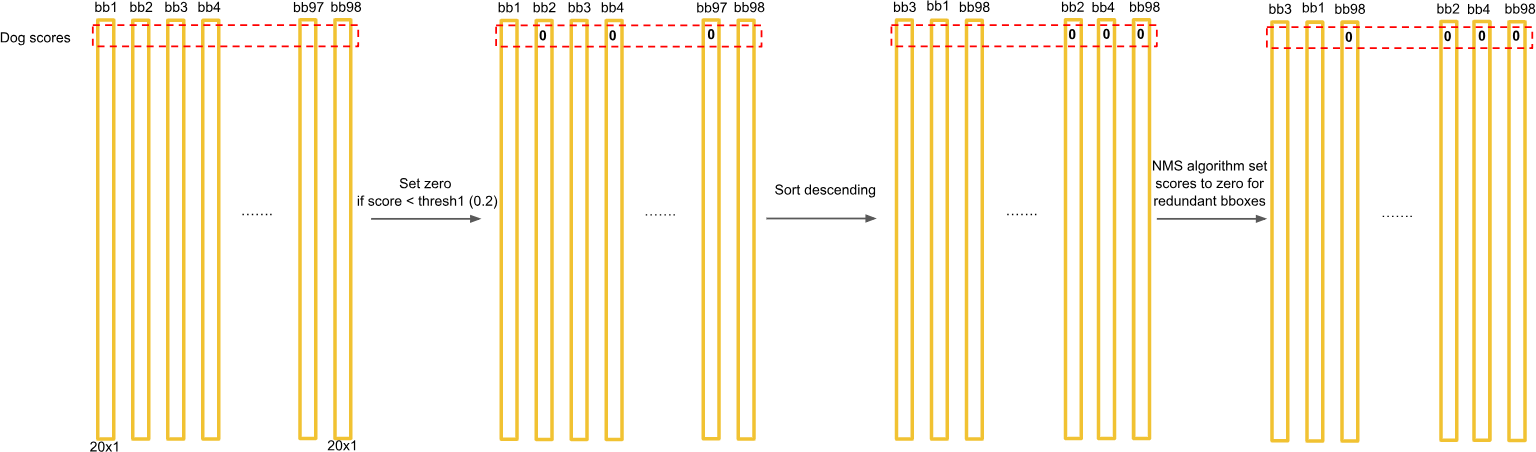
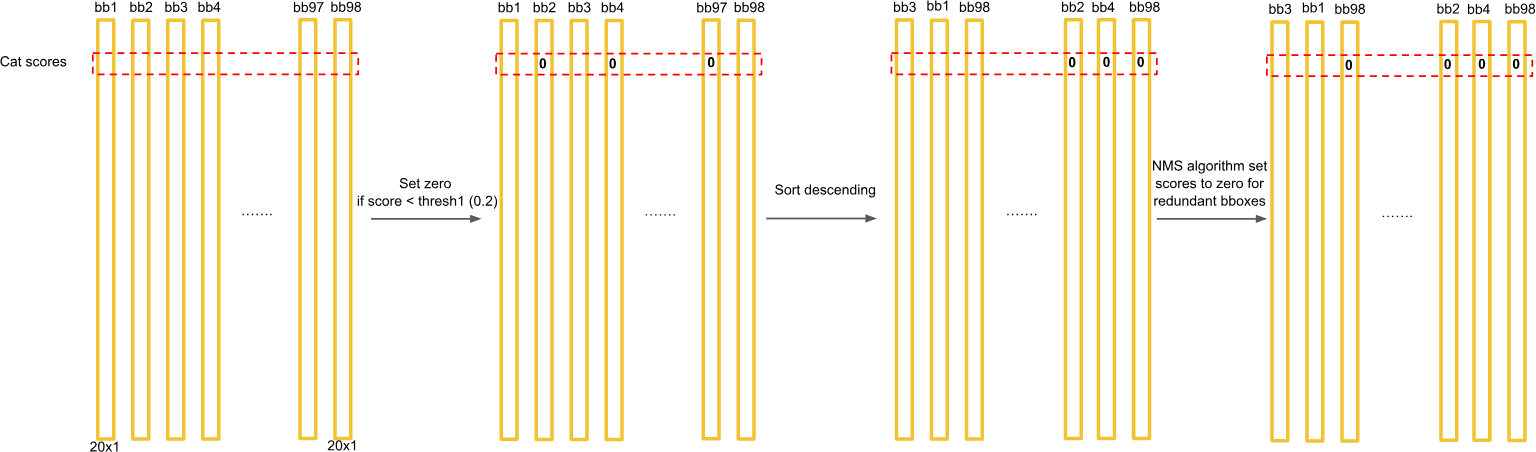
排序:将所有预测框按置信度分数从高到低排序。
选择:选取分数最高的框作为有效的检测结果。
抑制:剔除剩余框中与由于选中框的交并比(IOU)较高(例如 > 0.5)的所有框。
重复:对剩余的框重复选择和抑制步骤,直到没有框剩余。

最终检测得分的计算公式:

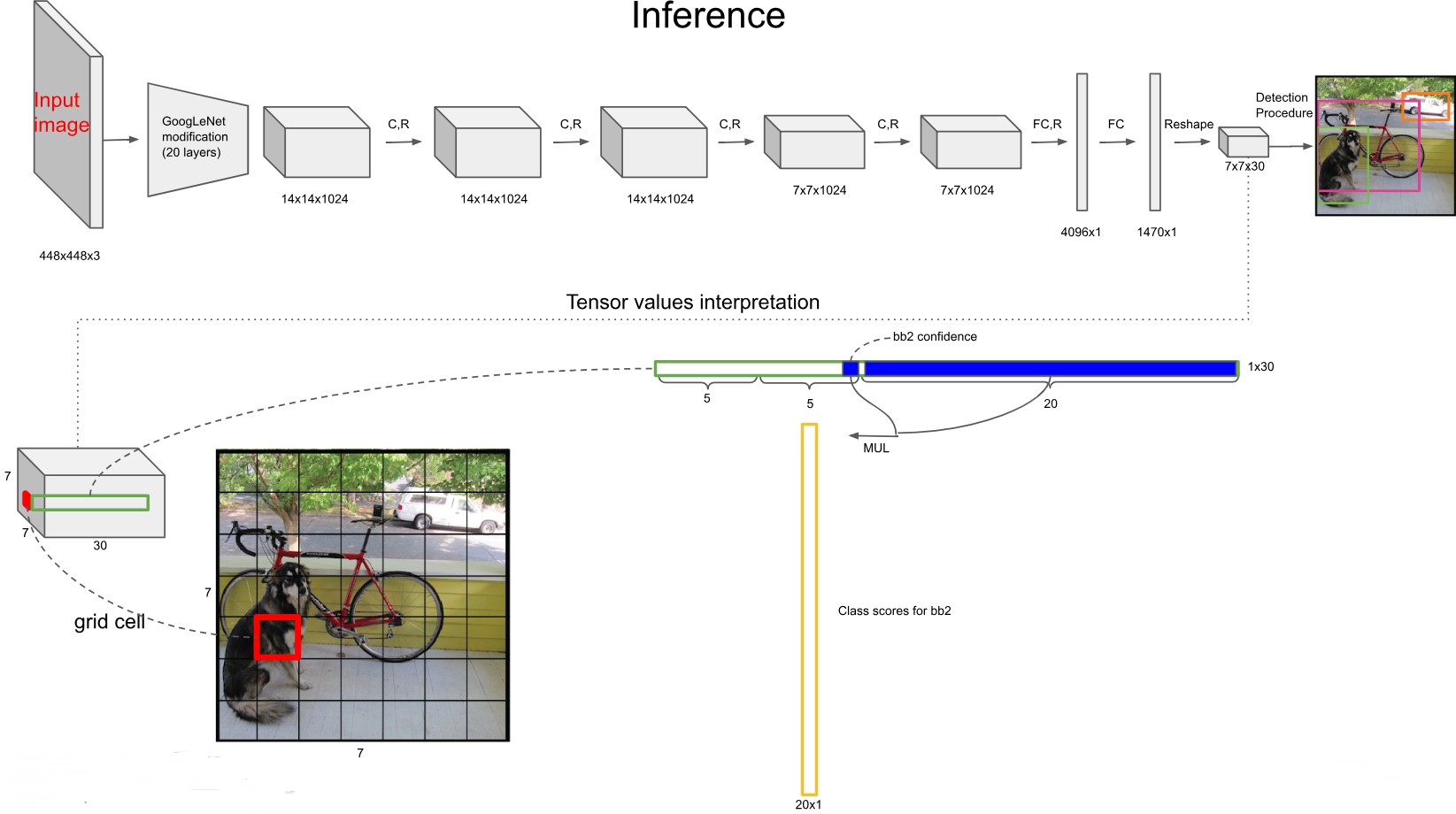
输出层的含义¶
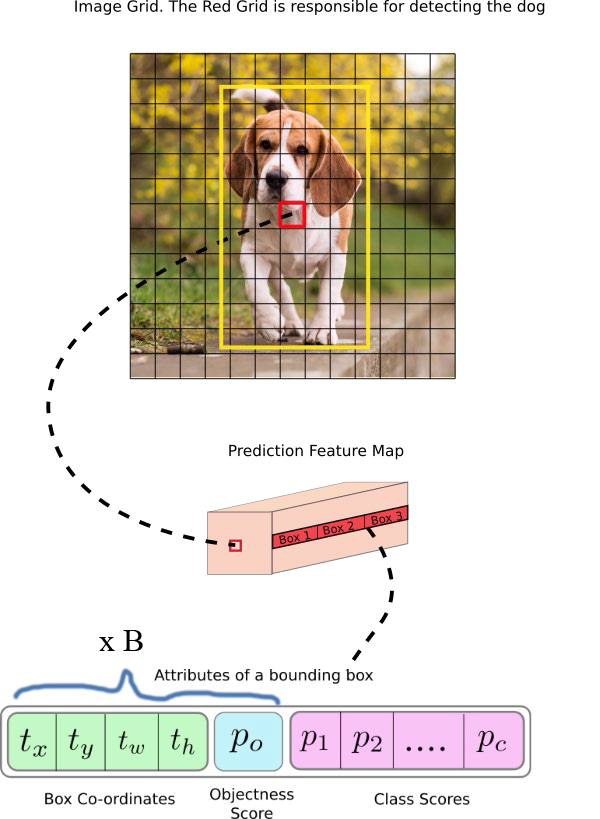
输出层的大小为 ,其含义如下:
:将原图分为 的网格
30个通道:每个格子中有30个数,分别对应:
2个边界框的位置信息: 共 个值
2个边界框的置信度:共2个值
20个类别的概率(VOC数据集有20个类别):共20个值
总计:
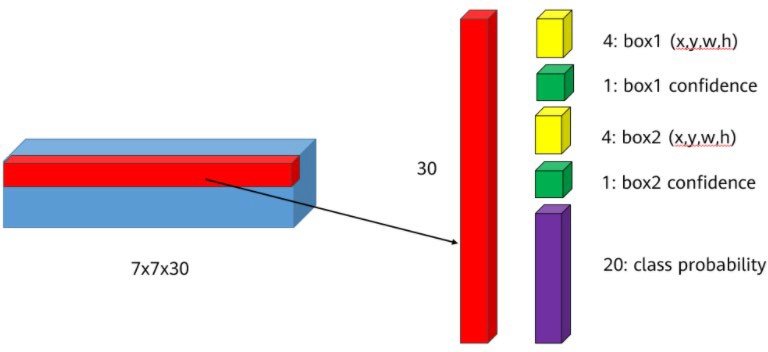
该图详细展示了YOLOv1输出张量的结构:每个网格预测两个边界框,并共享一组类别概率。
位置信息 的含义:
:目标中心点相对于网格左上角的偏移(归一化到0-1)
:目标的宽和高相对于整幅图像的比例
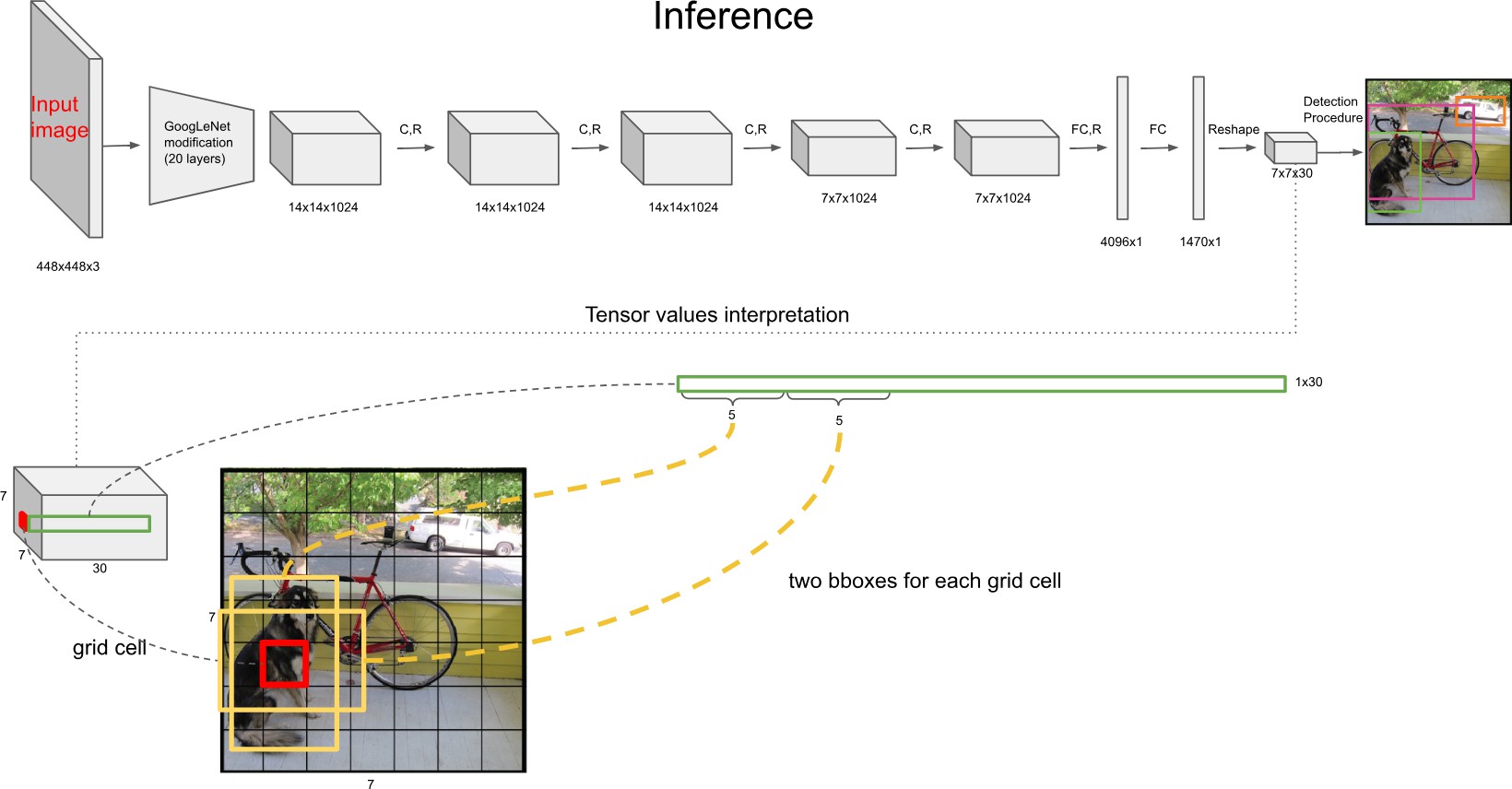
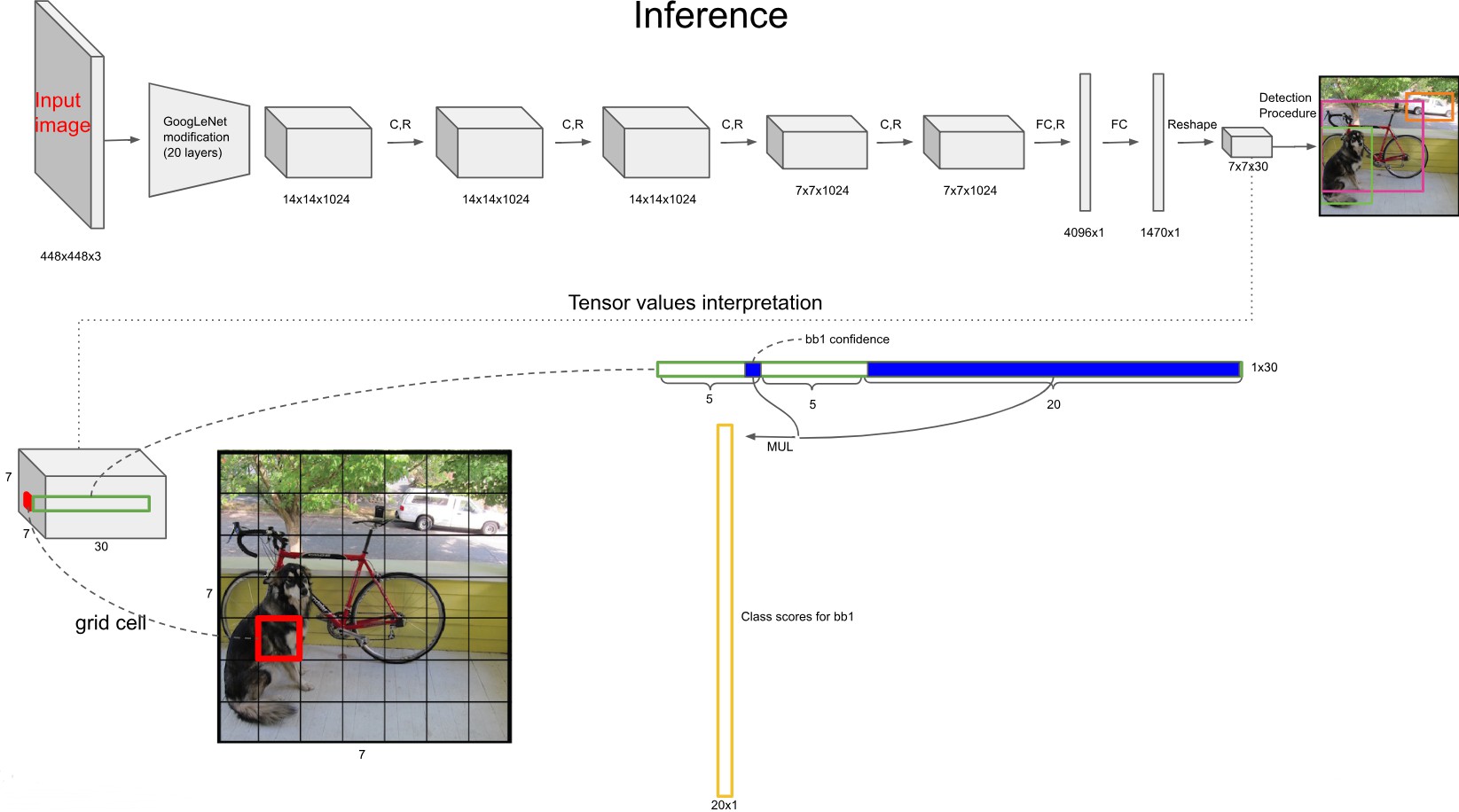
YOLOv1 损失函数¶
YOLOv1的损失函数由三部分构成:
1. 位置损失(Localization Loss):
2. 置信度损失(Confidence Loss):
3. 类别损失(Classification Loss):
总损失:
其中:
:增加位置损失的权重
:降低无目标格子的置信度损失权重
:指示函数,当第 个格子的第 个边框负责预测目标时,其值为 1(即该格子包含目标,且该边框与真实框的 IOU 最高)。否则为 0。
:指示函数,当第 个格子的第 个边框不负责预测任何目标时,其值为 1。否则为 0。(注:此项仅惩罚背景框的置信度误差)。
使用 和 是为了让小目标的位置误差更敏感
真实值(Ground Truth)的计算:
(真实置信度):对于负责预测目标的单元格,,即预测边框与真实边框之间的交并比。对于不包含目标的单元格,。注: 是网络预测的置信度。
(真实类别概率):采用独热编码(one-hot encoding)。如果单元格 中的目标属于类别 ,则 ,否则 。注: 是网络预测的类别概率。
YOLOv1 优缺点¶

优点:
运行速度快,可以达到实时检测
背景预测错误的情况比较少(利用全局信息)
端到端训练,简单高效
缺点:
对于小目标和密集目标的效果不好
定位精度不如Faster R-CNN
每个网格只能预测一个类别,限制了检测能力
YOLOv2 改进¶
YOLOv2网络相较于YOLOv1在以下几个方面有改进:
| 改进策略 | 说明 |
|---|---|
| Batch Normalization | 在每个卷积层后添加BN层,加速收敛,提升2%的mAP |
| High Resolution Classifier | 使用 分辨率微调分类网络 |
| Anchor Boxes | 引入Anchor机制,提升召回率 |
| K-means Clusters | 使用K-means聚类得到更好的先验框 |
| Direct Location Prediction | 约束边框中心在网格内 |
| Fine-Grained Features | 使用passthrough层融合细粒度特征 |
| Multi-Scale Training | 多尺度训练增强鲁棒性 |
注:mAP(mean Average Precision,平均精度均值) 是目标检测的标准评估指标。计算方法如下:
对于每个类别,在不同置信度阈值下计算精确率(Precision)和召回率(Recall),得到精确率-召回率(PR)曲线。
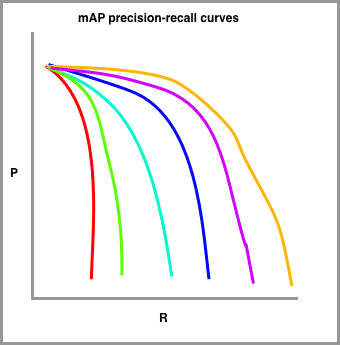
计算该类别的平均精度(AP),即PR曲线下的面积
mAP是所有类别AP值的平均:,其中 是类别总数
Better:更高的精度
Faster:更快的速度
Stronger:更强的泛化能力(YOLO9000可检测9000+类别)
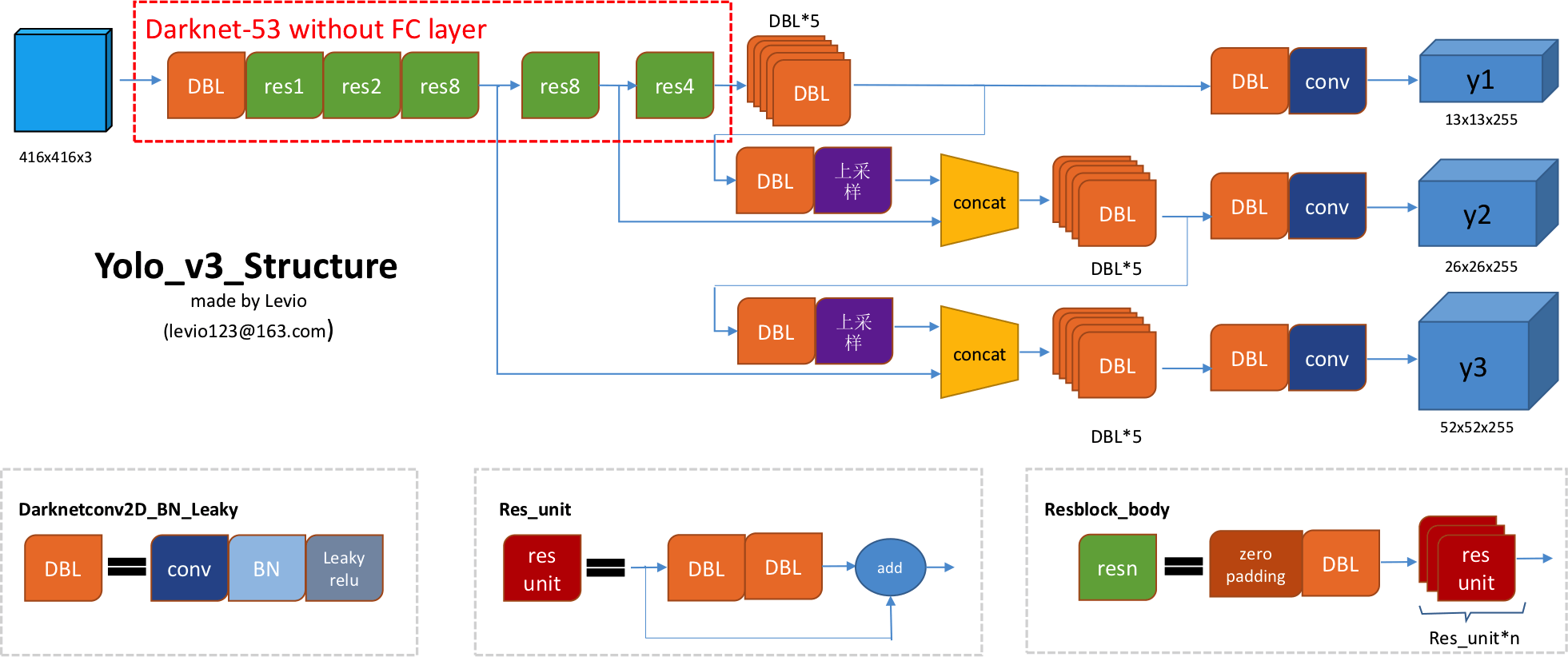
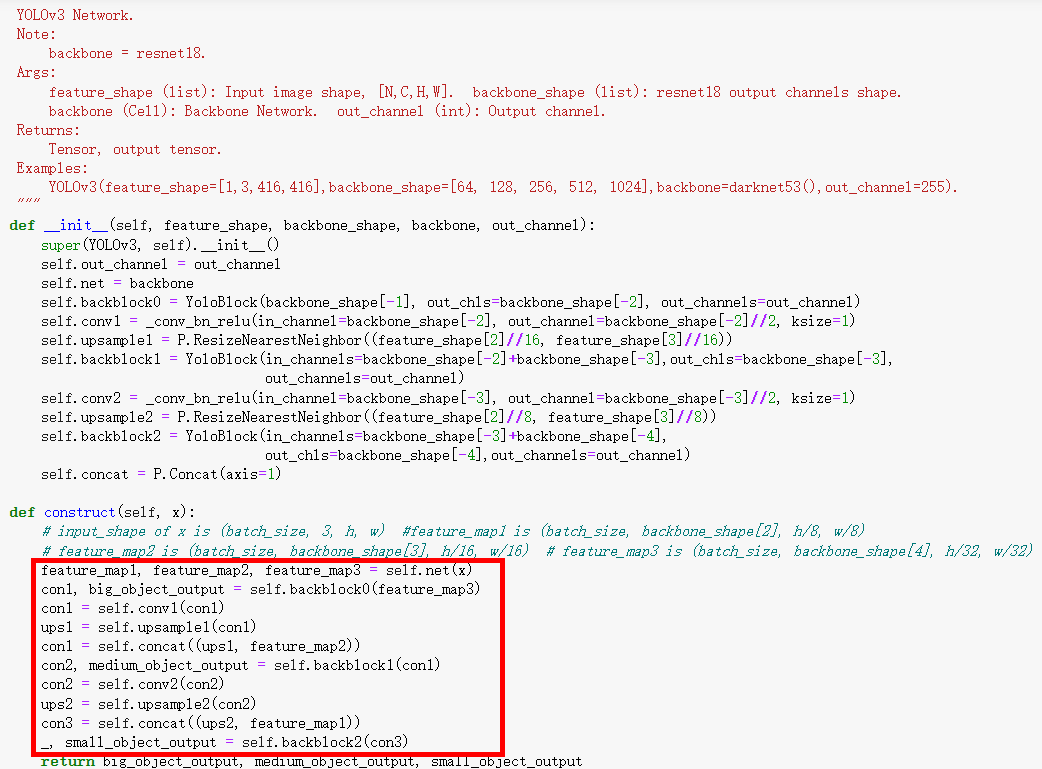
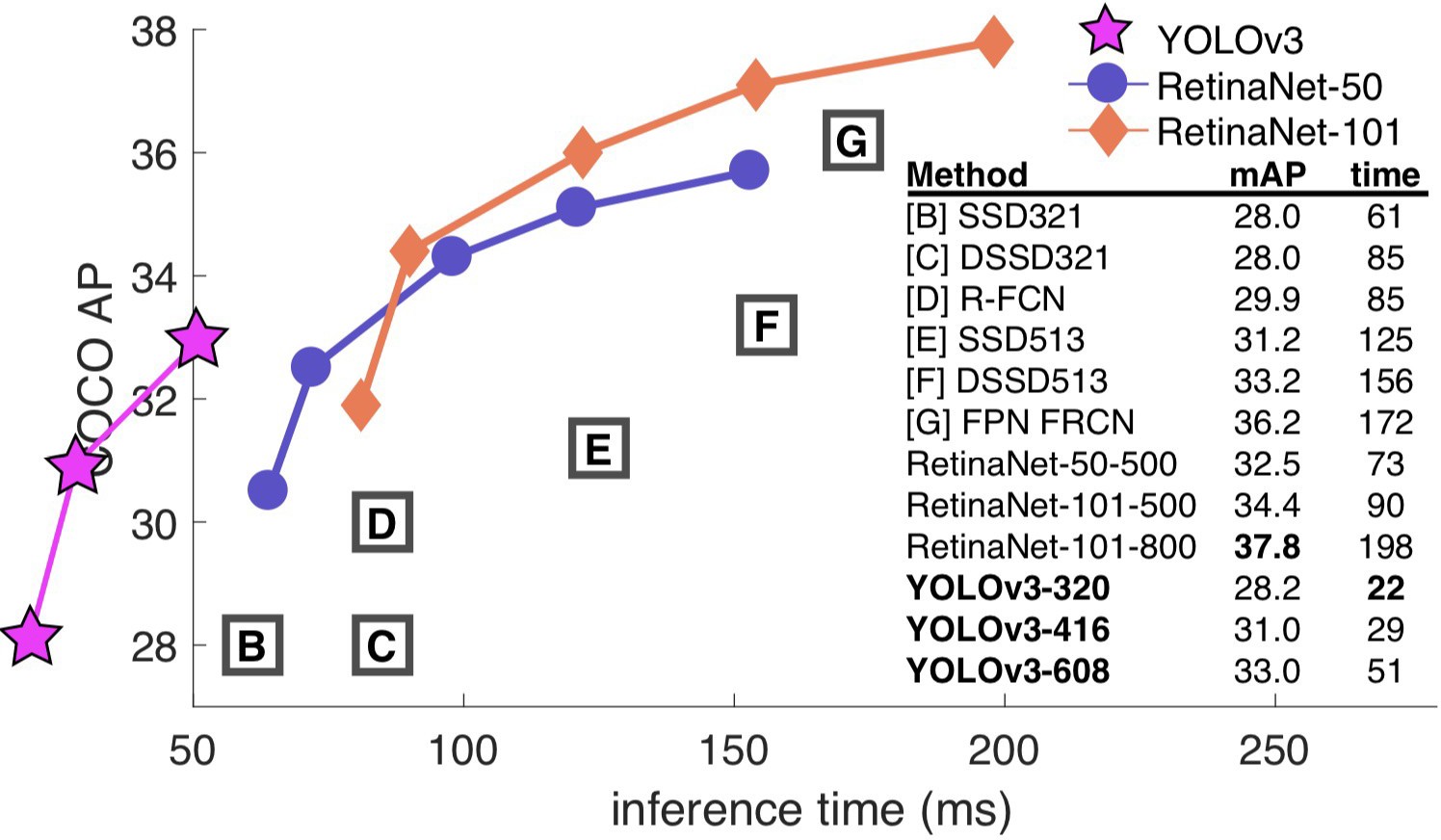
YOLOv3 多尺度检测¶

YOLOv3使用大、中、小三种不同的尺度进行单元格划分,分别对大目标、中等大小目标、小目标进行检测:
| 特征图尺度 | 输入尺寸 | Stride | 检测目标 |
|---|---|---|---|
| 32 | 大目标 | ||
| 16 | 中等目标 | ||
| 8 | 小目标 |
通过FPN(Feature Pyramid Network)结构融合不同层次的特征。
YOLOv3 网格预测¶
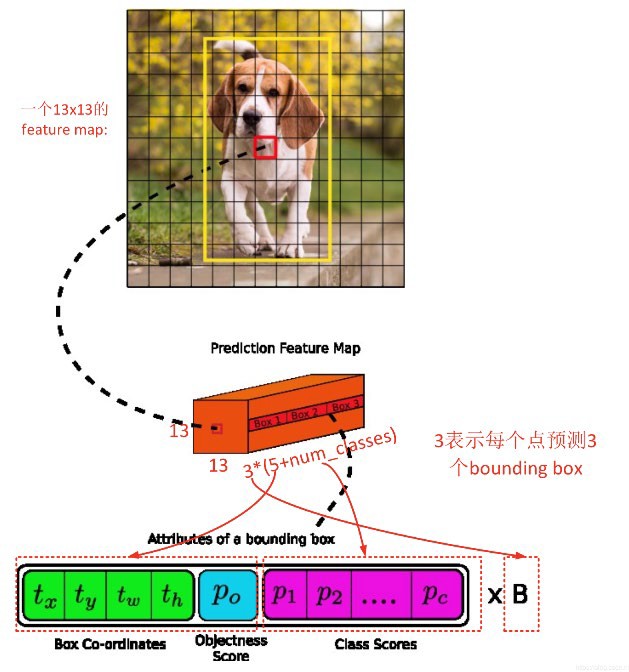
对于尺度为 的feature map,每个网格预测3个Bounding Box。
每个Bounding Box有85个系数:
坐标信息: = 4个值
目标置信度:1个值
类别概率:80个值(COCO数据集80类)
总计:
输出张量形状:
输出层可视化¶
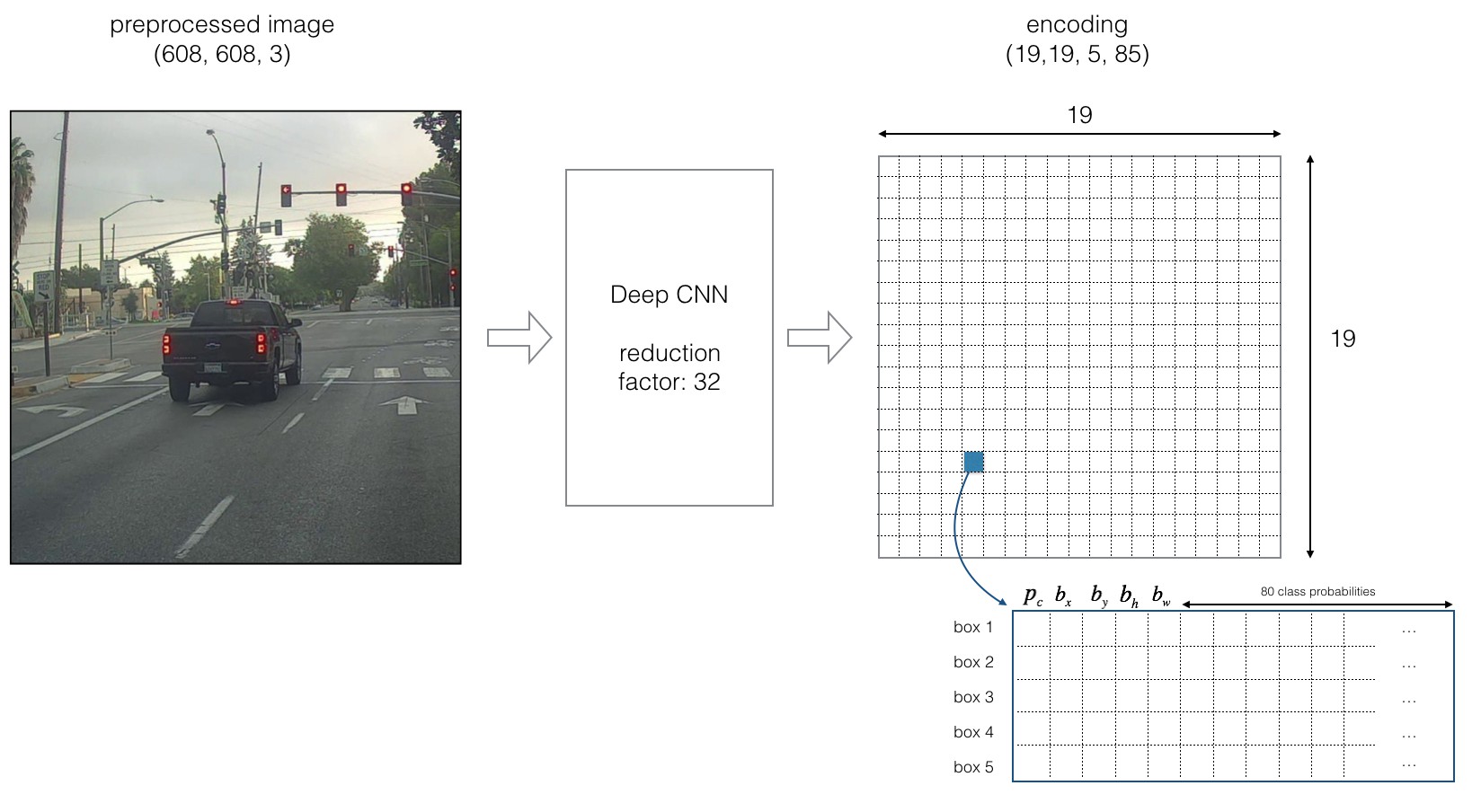
该图展示了YOLOv1输出张量的详细结构:19x19的网格,每个网格单元预测5个边界框及其自己的80个类别概率集合。
Anchor 先验框¶
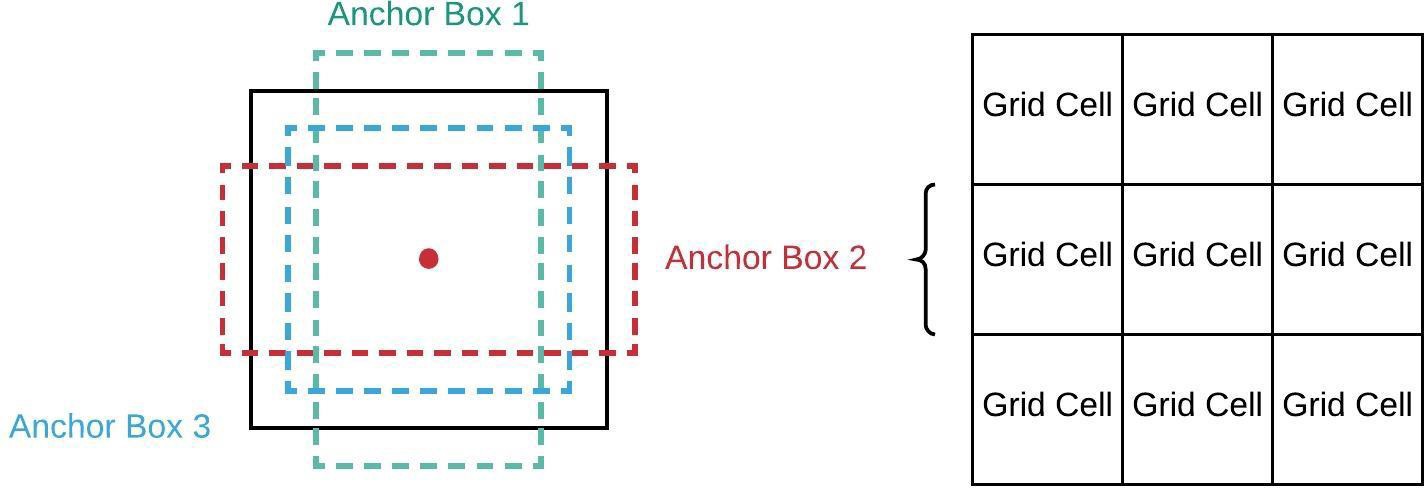
Anchor是指预定义的框集合,其宽度和高度与数据集中对象的宽度和高度相匹配。
Anchor的作用:
提供不同尺度和长宽比的先验
网络预测相对于Anchor的偏移量,而非直接预测坐标
通过K-means聚类从数据集中学习得到
YOLOv3使用9个Anchor,分配给3个尺度:
大尺度():3个大Anchor
中尺度():3个中Anchor
小尺度():3个小Anchor
Anchor 匹配与解码¶
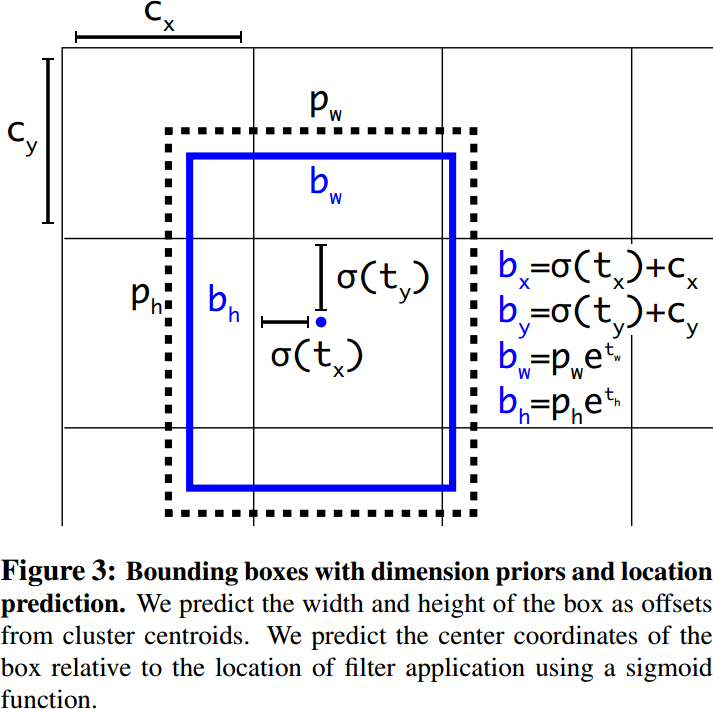
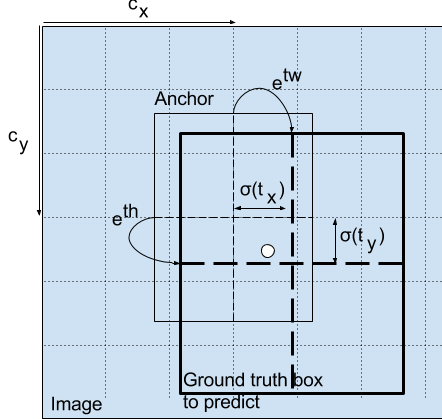
YOLOv3沿用了YOLOv2中关于先验框的技巧,使用K-means对数据集中的标签进行聚类,得到9个先验框。
边框解码公式:
其中:
:网络预测的原始值
:网格左上角坐标
:Anchor的宽高
:Sigmoid函数,将中心点约束在网格内
为什么使用指数函数?
无约束输出:网络的输出 可以是任意实数(正或负),但宽/高必须是正数。指数函数 保证了结果始终为正。
相对缩放:它允许模型预测相对于Anchor尺寸 的缩放因子。如果 ,则 (无变化)。如果 ,框变大;如果 ,框变小。这使得网络更容易学习对Anchor的“微调”。
边框解码代码示例¶
# YOLOv3 边框解码
box_xy = prediction[:, :, :, :, :2]
box_wh = prediction[:, :, :, :, 2:4]
box_confidence = prediction[:, :, :, :, 4:5]
box_probs = prediction[:, :, :, :, 5:]
# 中心点解码
box_xy = (self.sigmoid(box_xy) + grid) / \
P.Cast()(F.tuple_to_array((grid_size[1], grid_size[0])), ms.float32)
# 宽高解码
box_wh = P.Exp()(box_wh) * self.anchors / self.input_shape
# 置信度和类别概率
box_confidence = self.sigmoid(box_confidence)
box_probs = self.sigmoid(box_probs)YOLOv3 训练策略与损失函数¶
三个特征图解码的Anchor Box总数量:
这10647个box在训练和推理时使用方法不一样:
训练时:
10647个Box全部送入标签匹配函数
计算损失函数并反向传播
推理时:
选取一个置信度阈值,过滤掉低置信度的box
经过NMS(非极大值抑制)去除冗余框
输出最终的预测结果
YOLOv3 正负样本定义¶
预测框分为三类:正例(Positive)、负例(Negative)、忽略样例(Ignore)
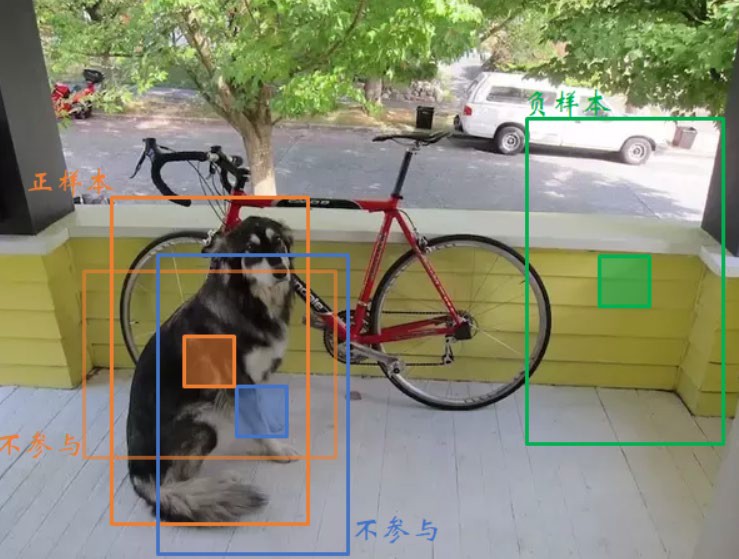
上图直观展示了正负样本的匹配过程。在训练过程中,我们需要为每一个预测框(共10647个)分配一个标签,以便计算损失。逻辑如下:
1. 正样本(Positive / Object):
定义:对于每一个真实目标(Ground Truth, GT),与其IOU重叠度最大的预测框被标记为正样本。
损失贡献:计算坐标损失、置信度损失(目标为1)和类别损失。
逻辑:该预测框是目标的“最佳”匹配,负责预测该目标。
2. 负样本(Negative / Background):
定义:既不是正样本,且与所有真实目标(GT)的 IOU 都低于阈值(通常为 0.5)的预测框。
损失贡献:仅计算置信度损失(目标为0)。
逻辑:该预测框明显是背景。如果它预测了较高的目标置信度,我们需要对其进行惩罚。
3. 忽略样本(Ignore):
定义:既不是正样本,但与某个真实目标(GT)的 IOU 高于阈值(0.5)的预测框。
损失贡献:不产生任何损失。
逻辑:该预测框“虽好但非最佳”。它与目标有显著重叠,但没有被选为主要预测框(通常是因为有另一个框的IOU更高)。我们既不希望将其视为背景(负样本)进行惩罚,也不强制它预测目标(因为已有最佳框负责)。
YOLOv3 损失函数¶

YOLOv3的损失函数分为三部分:
1. 坐标损失:使用均方误差
2. 置信度损失:使用二元交叉熵
3. 分类损失:使用Sigmoid + 二元交叉熵(替代Softmax)
取消了类别之间的互斥
可以使网络更加灵活,支持多标签分类

YOLOv5 模型结构¶
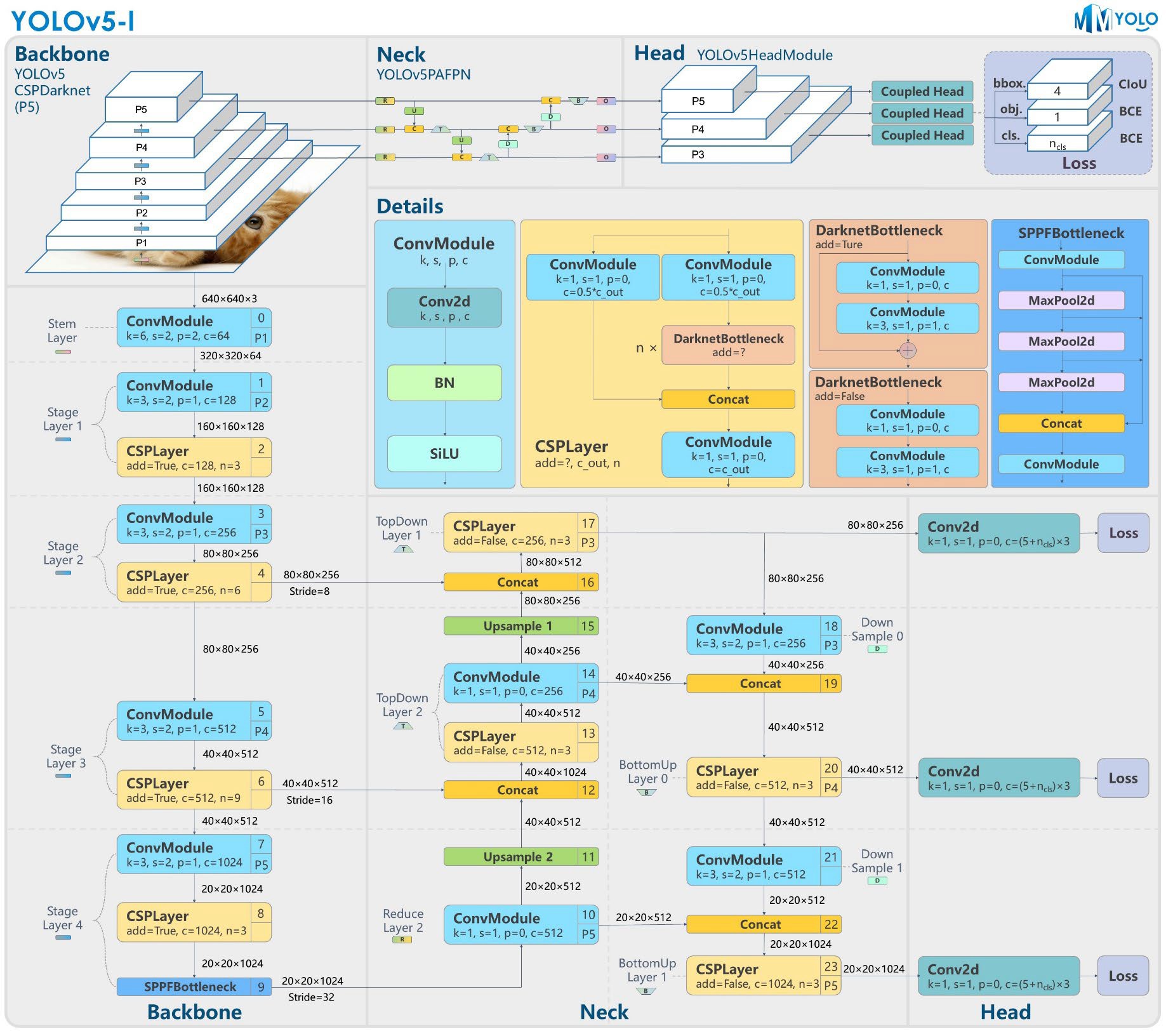
YOLOv5-l-P5 模型结构
YOLOv5-l-P6 模型结构
YOLOv5系列模型:
YOLOv5n:最小模型,适合移动端
YOLOv5s:小模型
YOLOv5m:中等模型
YOLOv5l:大模型
YOLOv5x:超大模型,最高精度
YOLOv5 数据增强¶
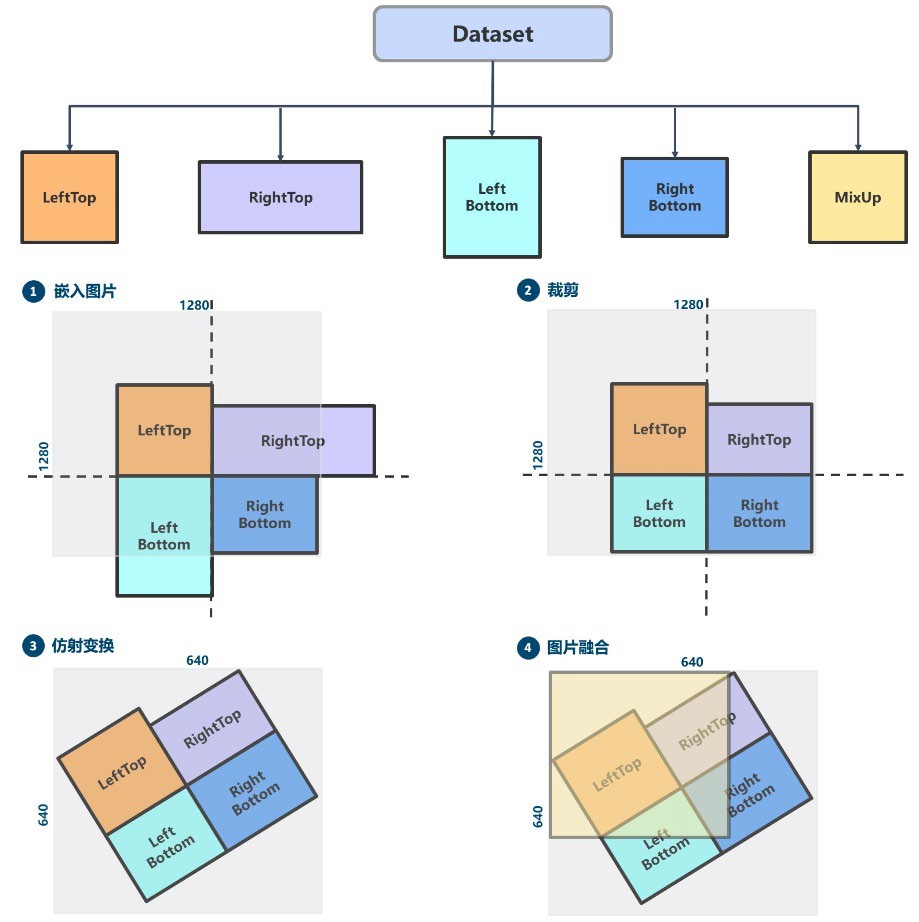
YOLOv5采用了多种数据增强策略:
| 增强方法 | 说明 |
|---|---|
| Mosaic | 四张图片拼接,概率为1(必定触发) |
| RandomAffine | 随机仿射变换(平移、旋转、缩放、错切) |
| MixUp | 两张图片混合,l/m/x模型概率0.1 |
| Albu库变换 | 图像模糊等增强 |
| HSV增强 | 颜色空间增强 |
| 随机水平翻转 | 常规增强 |
注意:small和nano两个版本不使用MixUp,因为小模型能力有限,不适合使用强数据增强。
Mosaic 马赛克数据增强¶

Mosaic属于混合类数据增强,需要4张图片拼接,相当于增加了训练的batch size。
运行过程:
随机生成拼接后4张图的交接中心点坐标
随机选出另外3张图片的索引及读取对应标注
对每张图片采用保持宽高比的resize操作缩放到指定大小
按照上下左右规则,计算每张图片在输出图片中的位置
利用裁剪坐标将缩放后的图片裁剪,贴到计算出的位置
其余位置填充114像素值
对标注进行相应处理
注意:拼接后图片面积扩大4倍(640×640 → 1280×1280),需要配合RandomAffine恢复到原始尺寸。
随机仿射变换¶
随机仿射变换包括平移、旋转、缩放、错切等几何增强操作。
RandomAffine有两个目的:
对图片进行随机几何仿射变换
将Mosaic输出的扩大4倍的图片还原为 尺寸
由于Mosaic和RandomAffine属于较强的增强操作,会引入噪声,需要对增强后的标注进行过滤:
| 过滤规则 | 说明 |
|---|---|
| 最小宽高 | 增强后的gt bbox宽高要大于 wh_thr |
| 面积比 | 增强后/增强前的面积比要大于 ar_thr |
| 最大宽高比 | 宽高比要小于 area_thr |
注意:由于旋转后标注框会变大导致不准确,目标检测中很少使用旋转数据增强。

YOLOv5s 网络结构图¶
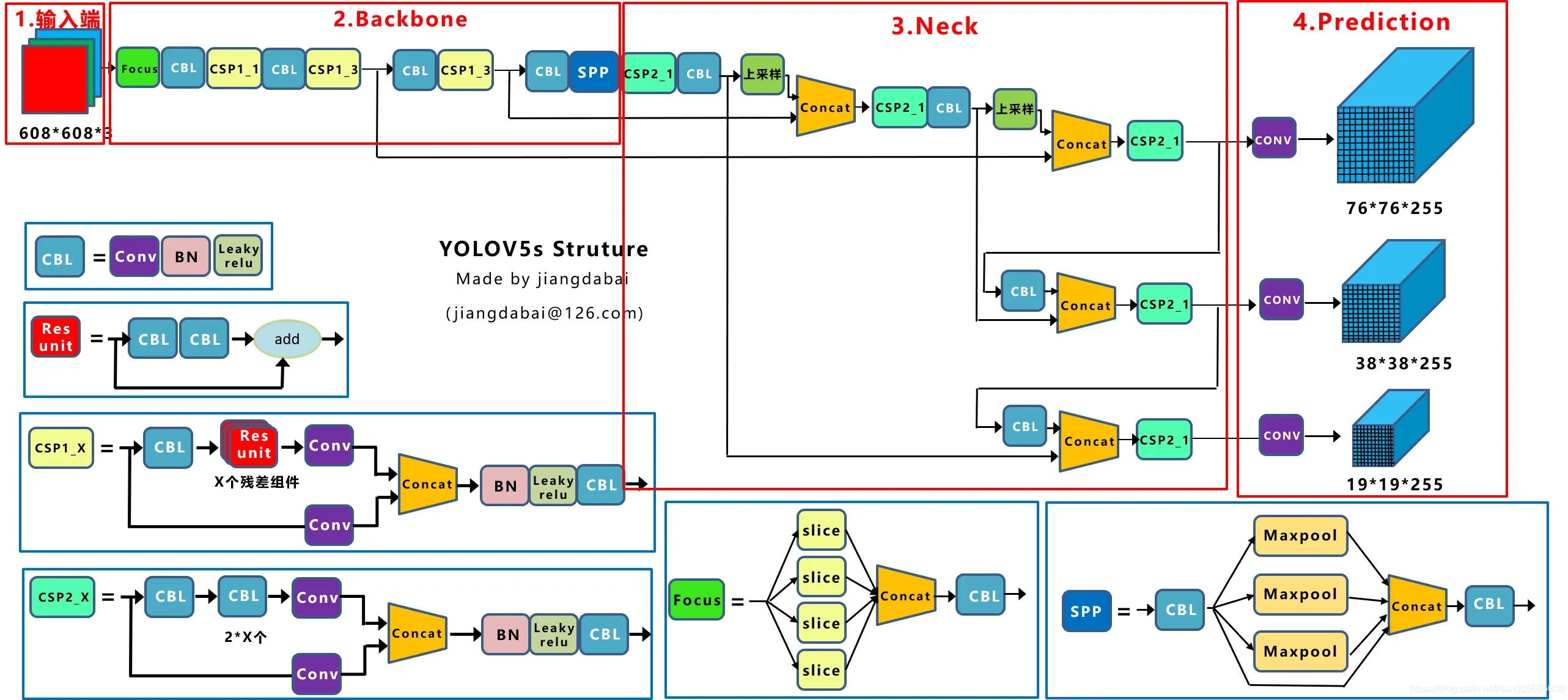
YOLOv5s的整体网络结构包括:
Backbone:提取特征的骨干网络
Neck:特征融合网络(FPN(Feature Pyramid Networks) + PAN(Path Aggregation Network))
Head:检测头,输出预测结果
Focus 结构¶
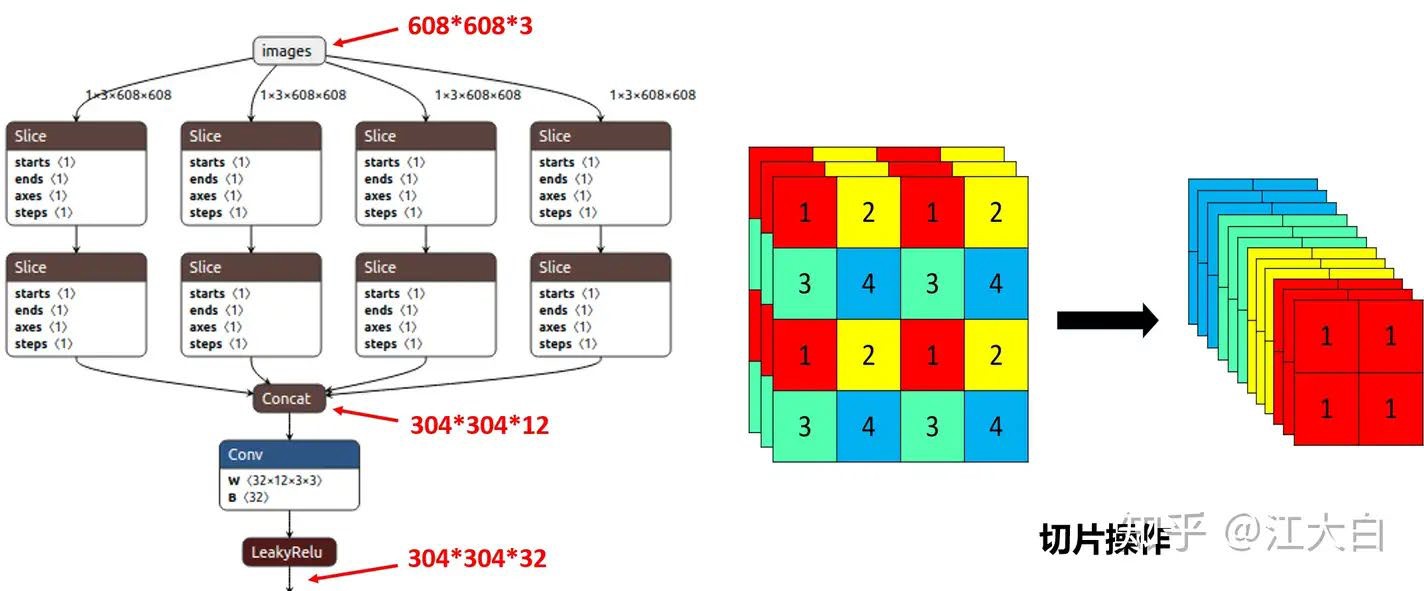
Focus结构是YOLOv5中新引入的,在YOLOv3和YOLOv4中并没有这个结构。
切片操作:
将 的图像切片后变成 的特征图
以YOLOv5s为例:
原始输入:
切片后:
经过32个卷积核卷积后:
Focus结构可以在不丢失信息的情况下进行下采样,同时减少计算量。
注意:YOLOv5s使用32个卷积核,而l/m/x版本使用更多卷积核。
CSP(Cross Stage Partial) 结构¶
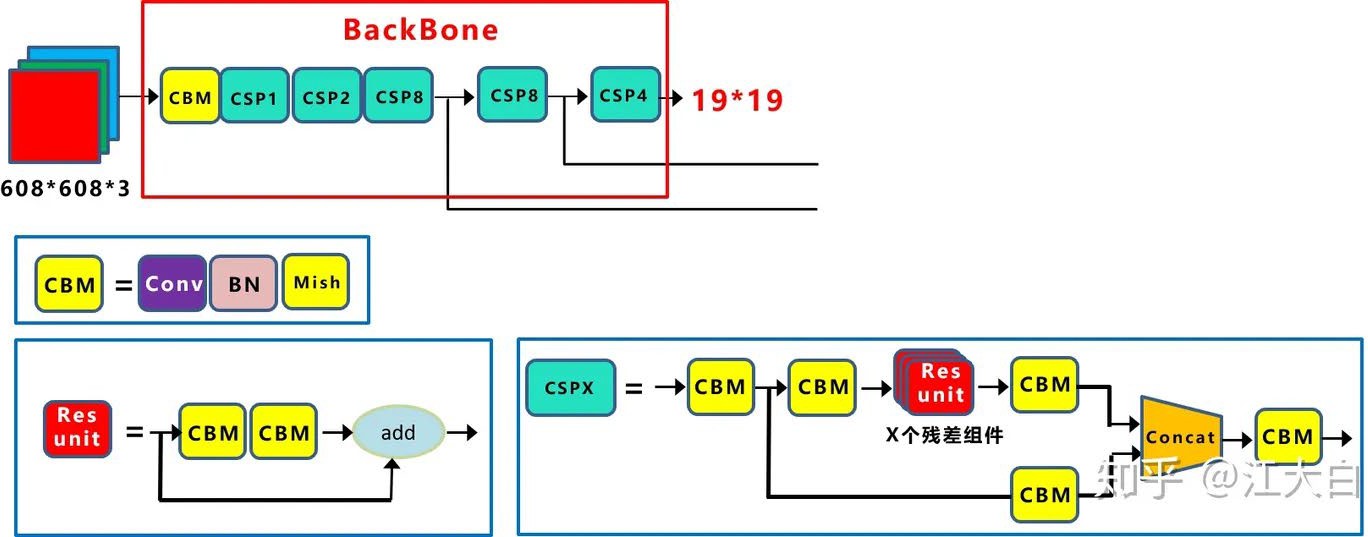
YOLOv4借鉴了CSPNet的设计思路,YOLOv5进一步发展:
YOLOv5设计了两种CSP结构:
| 结构 | 位置 | 特点 |
|---|---|---|
| CSP1_X | Backbone主干网络 | 包含残差块 |
| CSP2_X | Neck特征融合 | 不包含残差块 |
CSP结构的优势:
增强梯度的重用性
减少计算量
降低内存使用
Neck:FPN + PAN¶
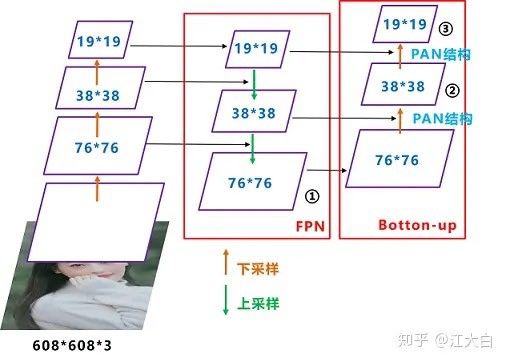
YOLOv5的Neck采用FPN + PAN结构:
FPN(Feature Pyramid Networks):
自顶向下的特征融合
将高层语义信息传递给低层
PAN(Path Aggregation Network):
自底向上的特征融合
将低层细节信息传递给高层
YOLOv5与YOLOv4的区别:
YOLOv4:使用普通卷积操作
YOLOv5:采用CSP2结构加强网络特征融合
正负样本匹配策略¶
正负样本匹配策略的核心是确定预测特征图的所有位置中哪些是正样本,哪些是负样本。一个好的匹配策略可以显著提升算法性能。
YOLOv5的匹配策略:采用anchor和gt_bbox的shape匹配度作为划分规则,同时引入跨邻域网格策略来增加正样本。
两个核心步骤:
Shape规则匹配:
对于任何一个输出层,直接采用shape规则匹配
计算GT Bbox和当前层Anchor的宽高比
如果宽高比例大于设定阈值,则匹配度不够,暂时丢掉该GT Bbox
跨邻域网格策略:
对于匹配上的GT Bbox,计算其落在哪个网格内
利用四舍五入规则,找出最近的两个网格
这三个网格都负责预测该GT Bbox
正样本数相比之前的YOLO系列至少增加了三倍
YOLOv5 Anchor 匹配¶
YOLOv5是Anchor-based目标检测算法,其Anchor size获取方式与YOLOv3类似,也是使用聚类获得。
与YOLOv3的区别:
YOLOv3:基于IOU的聚类
YOLOv5:使用形状上的宽高比作为聚类准则(shape-match)
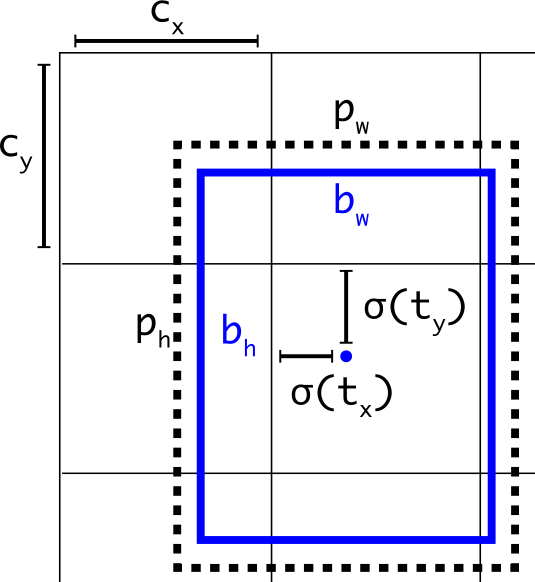
YOLOv5 回归公式改进¶
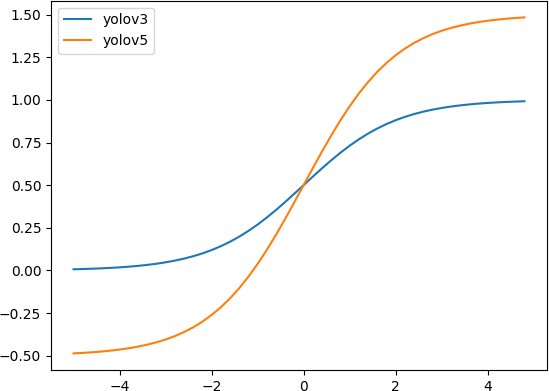
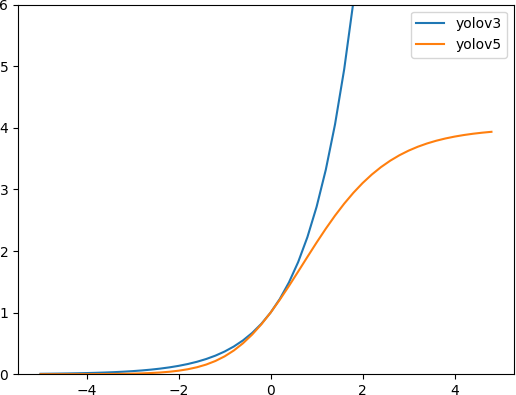
改进之处:
中心点坐标范围:从 调整至
新的中心点设置能更好的预测到0和1
有助于更精准回归出box坐标
宽高范围:从 调整至
YOLOv3中 是无界的,会导致梯度失控,造成训练不稳定
YOLOv5的改进优化了此问题
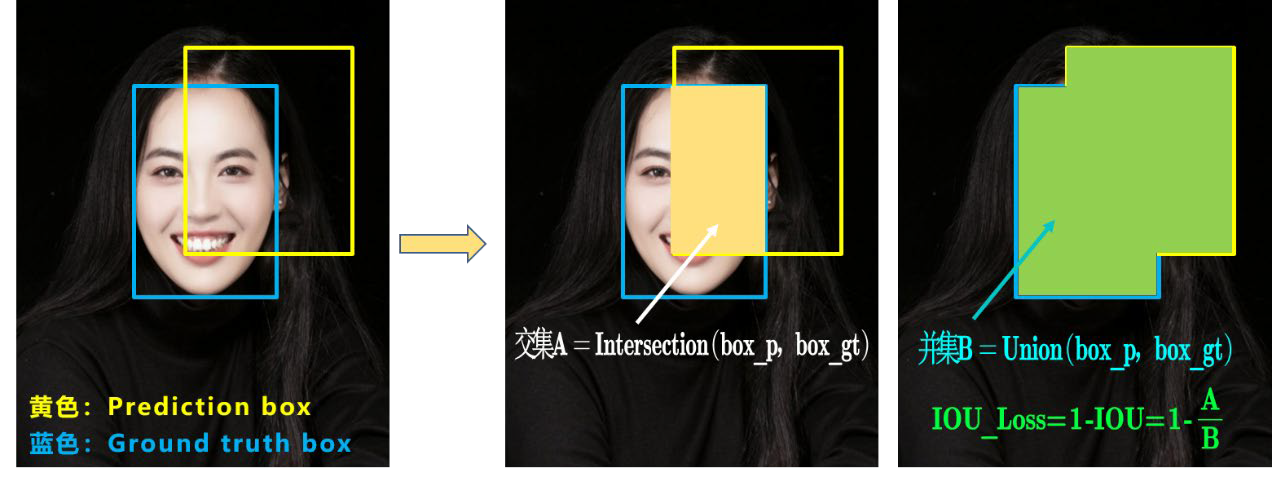
IOU 的两个问题¶

问题1:当预测框和目标框不相交时
IOU = 0,无法反映两个框距离的远近
损失函数不可导
IOU Loss无法优化两个框不相交的情况
问题2:当两个预测框大小相同时
两个IOU也相同
IOU Loss无法区分两者相交情况的不同
GIOU(Generalized IOU)¶
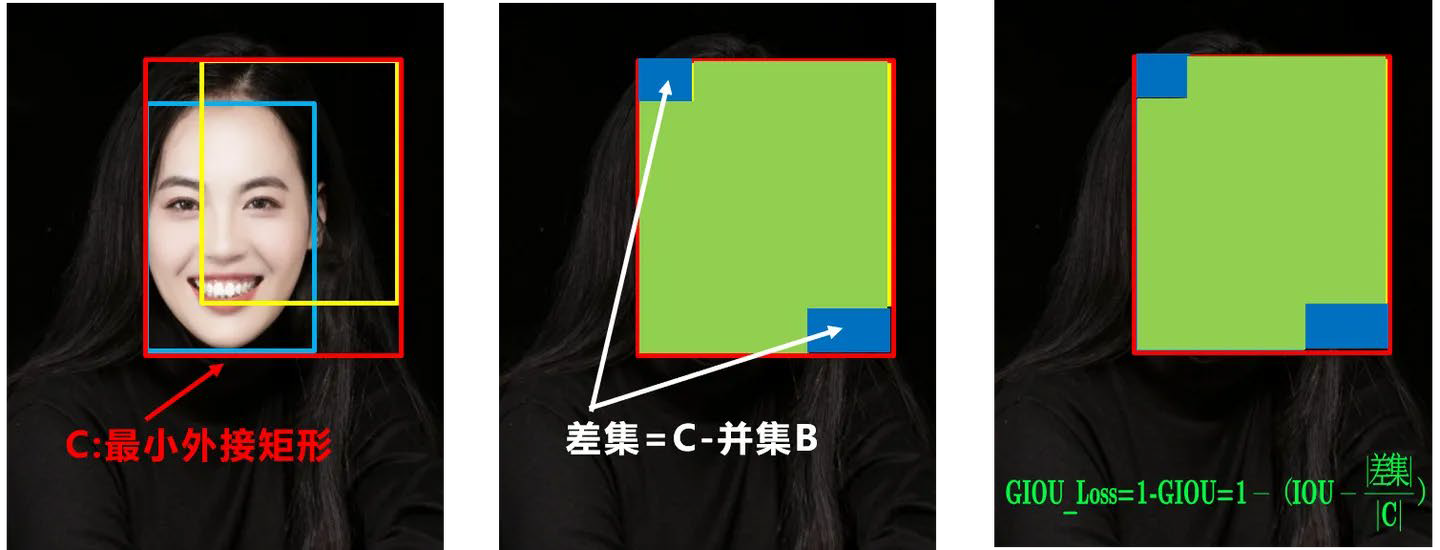
GIOU在IOU的基础上增加了相交尺度的衡量:
其中 是包含 和 的最小闭包区域。
GIOU Loss:
GIOU的优点:
当两个框不重叠时,GIOU仍然可以提供梯度
取值范围:

DIOU(Distance IOU)¶

好的目标框回归函数应该考虑三个重要几何因素:
重叠面积
中心点距离
长宽比
DIOU考虑了中心点距离:
其中:
:预测框和目标框中心点的欧氏距离
:包含两个框的最小闭包的对角线长度
DIOU的优点:
直接最小化两个框中心点的距离
收敛速度更快
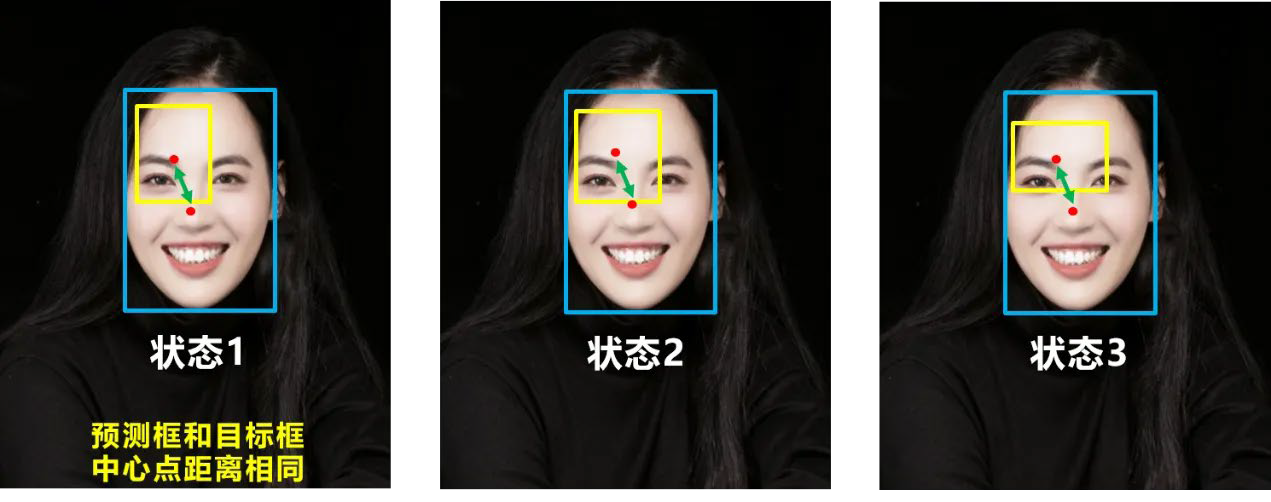
CIOU(Complete IOU)¶
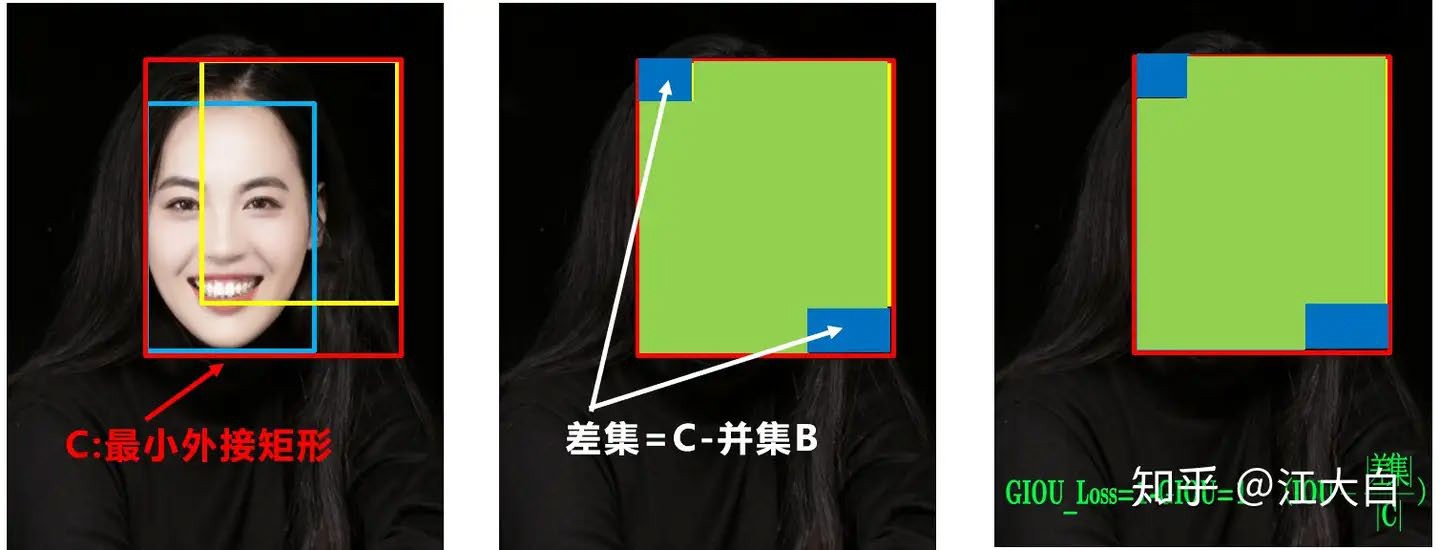
YOLOv5采用CIOU Loss作为Bounding Box的损失函数。
CIOU公式:
CIOU Loss:
其中 是衡量长宽比一致性的参数:
是权重系数:
CIOU同时考虑了:
重叠面积(IOU)
中心点距离()
长宽比()
NMS 非极大值抑制¶

注意:CIOU Loss中包含影响因子 ,涉及ground truth的信息,而测试推理时没有ground truth。
因此:
YOLOv4:在DIOU Loss的基础上采用DIOU-NMS
YOLOv5:采用加权NMS
从上图可以看出,采用DIOU-NMS后,原本被遮挡的物体(如摩托车)也可以被检出,相比传统NMS有明显提升。
DIOU-NMS的优势:
考虑了框之间的中心点距离
对于重叠物体的检测更加鲁棒
YOLO 系列发展时间线¶

YOLO系列的发展历程:
| 版本 | 年份 | 主要改进 |
|---|---|---|
| YOLOv1 | 2016 | 首次提出,单阶段检测器 |
| YOLOv2 | 2017 | Anchor机制、Batch Normalization |
| YOLOv3 | 2018 | 多尺度检测、Darknet-53 |
| YOLOv4 | 2020 | CSPDarknet、SPP、PAN |
| YOLOv5 | 2020 | Focus结构、自适应Anchor |
| YOLOv6-v8 | 2022-2023 | 持续优化,更好的速度-精度权衡 |
YOLO系列始终保持着在实时目标检测领域的领先地位。
在自定义数据集上训练 YOLOv5 目标检测器¶
在深度学习的帮助下,计算机视觉领域在过去十年中蓬勃发展。因此,许多流行的计算机视觉问题(例如具有实际工业用例的图像分类、对象检测和分割)开始达到前所未有的准确性。从 2012 年开始,每年都会设定一个新的基准。本次实验将从实用的角度来看待目标检测。我们将在自定义数据集上训练YOLOv5目标检测器。
下面我们先下载Yolov5代码并安装依赖 假设你已经创建好了虚拟环境:
conda create -n yolov5 --clone base
conda activate yolov5
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
pip install -r requirements.txt #install dependencie下载 王者数据集¶
自定义的带注释的图像数据集对于训练YOLOv5目标检测器至关重要它能够针对特定物体优化模型性能, 从而产生满足需求的检测器. Roboflow, LabelImg 等软件是近几年出现的免费标识工具,用于简化人工标识工作流程并制定标识标准.
由于我们将训练YOLOv5 PyTorch模型, 因此我们将以YOLOv5 pytorch格式下载数据集. YOLOv5的真实注释格式非常简单(示例如图 2 所示), 因此您可以自己编写一个脚本来完成此操作. 每个图像的每个边界框都有一个文本文件, 其中一行. 例如, 如果一张图像中有四个对象, 则文本文件将有四行包含类标签和边界框坐标. 每行的格式为
class_id center_x center_y width height

其中字段以空格分隔,坐标从 0 到 1 标准化。要从像素值转换为标准化 xywh,将 x 和框宽度除以图像的宽度,并将 y 和框高度除以图像的高度。
本次实验我们从Roboflow下载王者数据集, 当然同学们也可以运用标识软件自行标识
wget https://gitee.com/seven239236/ascend_-orange-pi-aipro/raw/master/king.zip
cd king
unzip -q king.zipYOLOV5_DIR = "../../../yolov5"
!tree -L 2 {YOLOV5_DIR}/king../../../yolov5/king
├── dataset
│ ├── images
│ └── labels
├── data.yaml
├── get_dataset.py
├── king.zip
├── labels
│ ├── 000006.xml
│ ├── 000007.xml
│ ├── 000008.xml
│ ├── 000009.xml
│ ├── 000010.xml
│ ├── 000011.xml
│ ├── 000012.xml
│ ├── 000013.xml
│ ├── 000014.xml
│ ├── 000015.xml
│ ├── 000016.xml
│ ├── 000017.xml
│ ├── 000018.xml
│ ├── 000019.xml
│ ├── 000020.xml
│ ├── 000021.xml
│ ├── 000022.xml
│ ├── 000023.xml
│ ├── 000024.xml
│ ├── 000025.xml
│ ├── 000026.xml
│ ├── 000027.xml
│ ├── 000028.xml
│ ├── 000029.xml
│ ├── 000030.xml
│ ├── 000031.xml
│ ├── 000032.xml
│ ├── 000033.xml
│ ├── 000034.xml
│ ├── 000035.xml
│ ├── 000036.xml
│ ├── 000037.xml
│ ├── 000039.xml
│ ├── 000040.xml
│ ├── 000041.xml
│ ├── 000042.xml
│ ├── 000044.xml
│ ├── 000045.xml
│ ├── 000054.xml
│ ├── 000060.xml
│ ├── 000065.xml
│ ├── 000066.xml
│ ├── 000067.xml
│ ├── 000068.xml
│ ├── 000069.xml
│ ├── 000074.xml
│ ├── 000076.xml
│ ├── 000077.xml
│ ├── 000078.xml
│ ├── 000082.xml
│ ├── 000084.xml
│ ├── 000086.xml
│ ├── 000087.xml
│ ├── 000090.xml
│ ├── 000095.xml
│ ├── 000096.xml
│ ├── 000097.xml
│ ├── 000098.xml
│ ├── 000099.xml
│ ├── 000100.xml
│ ├── 000102.xml
│ ├── 000103.xml
│ ├── 000104.xml
│ ├── 000106.xml
│ ├── 000107.xml
│ ├── 000113.xml
│ ├── 000114.xml
│ ├── 000115.xml
│ ├── 000117.xml
│ ├── 000119.xml
│ ├── 000122.xml
│ ├── 000123.xml
│ ├── 000127.xml
│ ├── 000130.xml
│ ├── 000131.xml
│ ├── 000134.xml
│ ├── 000138.xml
│ ├── 000140.xml
│ ├── 000142.xml
│ ├── 000143.xml
│ ├── 000144.xml
│ ├── 000148.xml
│ ├── 000150.xml
│ ├── 000152.xml
│ ├── 000154.xml
│ ├── 000155.xml
│ ├── 000156.xml
│ ├── 000157.xml
│ ├── 000158.xml
│ ├── 000159.xml
│ ├── 000160.xml
│ ├── 000162.xml
│ ├── 000163.xml
│ ├── 000164.xml
│ ├── 000166.xml
│ ├── 000167.xml
│ ├── 000168.xml
│ ├── 000171.xml
│ ├── 000173.xml
│ ├── 000175.xml
│ ├── 000177.xml
│ ├── 000179.xml
│ ├── 000181.xml
│ ├── 000182.xml
│ ├── 000183.xml
│ ├── 000185.xml
│ ├── 000189.xml
│ ├── 000192.xml
│ ├── 000196.xml
│ ├── 000199.xml
│ ├── 000204.xml
│ ├── 000205.xml
│ ├── 000207.xml
│ ├── 000208.xml
│ ├── 000210.xml
│ ├── 000215.xml
│ ├── 000216.xml
│ ├── 000217.xml
│ ├── 000219.xml
│ ├── 000226.xml
│ ├── 000227.xml
│ ├── 000230.xml
│ ├── 000231.xml
│ ├── 000233.xml
│ ├── 000234.xml
│ ├── 000235.xml
│ ├── 000236.xml
│ ├── 000240.xml
│ ├── 000243.xml
│ ├── 000245.xml
│ ├── 000246.xml
│ ├── 000247.xml
│ ├── 000251.xml
│ ├── 000253.xml
│ ├── 000254.xml
│ ├── 000255.xml
│ ├── 000256.xml
│ ├── 000257.xml
│ ├── 000259.xml
│ ├── 000261.xml
│ ├── 000262.xml
│ ├── 000263.xml
│ ├── 000264.xml
│ ├── 000265.xml
│ ├── 000266.xml
│ ├── 000268.xml
│ ├── 000269.xml
│ ├── 000270.xml
│ ├── 000272.xml
│ ├── 000273.xml
│ ├── 000275.xml
│ ├── 000277.xml
│ ├── 000279.xml
│ ├── 000280.xml
│ ├── 000281.xml
│ ├── 000283.xml
│ ├── 000286.xml
│ ├── 000292.xml
│ ├── 000295.xml
│ ├── 000297.xml
│ ├── 000300.xml
│ ├── 000301.xml
│ ├── 000305.xml
│ ├── 000306.xml
│ ├── 000307.xml
│ ├── 000308.xml
│ ├── 000310.xml
│ ├── 000312.xml
│ ├── 000313.xml
│ ├── 000318.xml
│ ├── 000319.xml
│ ├── 000322.xml
│ ├── 000329.xml
│ ├── 000330.xml
│ ├── 000331.xml
│ ├── 000332.xml
│ ├── 000333.xml
│ ├── 000334.xml
│ ├── 000338.xml
│ ├── 000339.xml
│ ├── 000340.xml
│ ├── 000341.xml
│ ├── 000342.xml
│ ├── 000343.xml
│ ├── 000344.xml
│ ├── 000345.xml
│ ├── 000346.xml
│ ├── 000349.xml
│ ├── 000350.xml
│ ├── 000352.xml
│ ├── 000353.xml
│ ├── 000354.xml
│ ├── 000357.xml
│ ├── 000358.xml
│ ├── 000364.xml
│ ├── 000366.xml
│ ├── 000369.xml
│ ├── 000370.xml
│ ├── 000373.xml
│ ├── 000376.xml
│ ├── 000380.xml
│ ├── 000384.xml
│ ├── 000385.xml
│ ├── 000386.xml
│ ├── 000388.xml
│ ├── 000389.xml
│ ├── 000390.xml
│ ├── 000391.xml
│ ├── 000392.xml
│ ├── 000393.xml
│ ├── 000394.xml
│ ├── 000395.xml
│ ├── 000397.xml
│ ├── 000398.xml
│ ├── 000399.xml
│ ├── 000400.xml
│ ├── 000402.xml
│ ├── 000403.xml
│ ├── 000415.xml
│ ├── 000416.xml
│ ├── 000417.xml
│ ├── 000418.xml
│ ├── 000419.xml
│ ├── 000421.xml
│ ├── 000422.xml
│ ├── 000424.xml
│ ├── 000425.xml
│ ├── 000426.xml
│ ├── 000427.xml
│ ├── 000428.xml
│ ├── 000430.xml
│ ├── 000431.xml
│ ├── 000433.xml
│ ├── 000434.xml
│ ├── 000436.xml
│ ├── 000783.xml
│ ├── 000784.xml
│ ├── 000785.xml
│ ├── 000786.xml
│ ├── 000788.xml
│ ├── 000789.xml
│ ├── 000792.xml
│ ├── 000795.xml
│ ├── 000798.xml
│ ├── 000842.xml
│ ├── 000843.xml
│ ├── 000844.xml
│ ├── 000845.xml
│ ├── 000942.xml
│ ├── 000943.xml
│ ├── 000944.xml
│ ├── 000946.xml
│ ├── 000948.xml
│ ├── 000952.xml
│ ├── 001060.xml
│ ├── 001061.xml
│ ├── 001087.xml
│ ├── 001088.xml
│ ├── 001089.xml
│ ├── 001093.xml
│ ├── 001242.xml
│ ├── 001244.xml
│ ├── 001246.xml
│ └── 001250.xml
├── README.docx
├── statistics.py
├── train
│ ├── images
│ ├── labels
│ ├── labels.cache
│ └── val
├── val
│ ├── images
│ ├── labels
│ └── labels.cache
└── video2images.py
12 directories, 272 files
import yaml
config = {'path': '{YOLOV5_DIR}/king',
'train': '{YOLOV5_DIR}/king/train',
'val': '{YOLOV5_DIR}/king/val',
'nc': 8,
'names': ['hero','dogface','monster','tower','grass','dragon','buff','blood']}
with open("{YOLOV5_DIR}/king/data.yaml", "w") as file:
yaml.dump(config, file, default_flow_style=False)训练模型¶
YOLOv5 的五个变体,从为在移动和嵌入式设备上运行而构建的最微型 YOLOv5 nano 模型到另一端的 YOLOv5 XLarge。对于今天的实验,我们将利用基本模型 YOLOv5s,它在准确性和速度之间提供了良好的平衡。
import os
filename = "{YOLOV5_DIR}/yolov5s.pt"
if os.path.exists(filename):
print(f"{filename} already exists in the current directory.")
else:
!wget https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.ptyolov5s.pt already exists in the current directory.
YOLOv5 有大约 30 个超参数,用于各种训练设置。这些在 data/hyps/hyp.scratch-low.yaml 中定义,用于从头开始进行低增强 COCO 训练,放置在 /data 目录中。训练数据超参数如下所示,这对于产生良好的结果非常重要,因此请确保在开始训练之前正确初始化这些值。在本教程中,我们将简单地使用默认值,这些值从头开始针对 YOLOv5 COCO 训练进行了优化。
包括学习率、weight_decay 和 iou_t(IoU 训练阈值)等,以及一些数据增强超参数,例如translate、scale、mosaic、mixup 和copy_paste。 mixup:0.0 表示不应应用 mixup 数据增强。
!cat {YOLOV5_DIR}/data/hyps/hyp.scratch-low.yaml# Ultralytics YOLOv5 🚀, AGPL-3.0 license
# Hyperparameters for low-augmentation COCO training from scratch
# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear
# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)
接下来,可以简单地看一下 YOLOv5s 网络架构的结构,尽管与训练数据超参数不同,这里我们不会修改模型配置文件。 MS COCO 数据集的nc(类别数)设置为 80,backbone 用于特征提取,后面是 head 用于检测。
!cat {YOLOV5_DIR}/models/yolov5s.yaml# Ultralytics YOLOv5 🚀, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
#设置简单的超参数
SIZE = 640
BATCH_SIZE = 128
EPOCHS = 20
MODEL = "yolov5s"
WORKERS = 1
PROJECT = "king_project"
RUN_NAME = f"{MODEL}_size{SIZE}_epochs{EPOCHS}_batch{BATCH_SIZE}_small"# 从yolov5目录运行训练
cmd = f"cd {YOLOV5_DIR} && python train.py --img {SIZE} --batch {BATCH_SIZE} --epochs {EPOCHS} --data king/data.yaml --weights {MODEL}.pt --workers {WORKERS} --project {PROJECT} --name {RUN_NAME} --exist-ok"
print(f"Running: {cmd}")
!{cmd}/home/jack/workspace/computer_vision_class_en/yolov5/utils/general.py:32: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
import pkg_resources as pkg
train: weights=yolov5s.pt, cfg=, data=king/data.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=20, batch_size=128, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, evolve_population=data/hyps, resume_evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=1, project=king_project, name=yolov5s_size640_epochs20_batch128_small, exist_ok=True, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest, ndjson_console=False, ndjson_file=False
remote: Enumerating objects: 969, done.
remote: Counting objects: 100% (328/328), done.
remote: Compressing objects: 100% (69/69), done.
remote: Total 969 (delta 289), reused 259 (delta 259), pack-reused 641 (from 4)
Receiving objects: 100% (969/969), 1.07 MiB | 2.52 MiB/s, done.
Resolving deltas: 100% (600/600), completed with 80 local objects.
From https://github.com/ultralytics/yolov5
12be4996..781b9d57 master -> origin/master
* [new branch] RizwanMunawar-patch-1 -> origin/RizwanMunawar-patch-1
github: ⚠️ YOLOv5 is out of date by 108 commits. Use 'git pull' or 'git clone https://github.com/ultralytics/yolov5' to update.
YOLOv5 🚀 v7.0-342-g12be4996 Python-3.10.14 torch-2.2.1 CUDA:0 (NVIDIA GeForce RTX 3090 Ti, 24110MiB)
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Comet: run 'pip install comet_ml' to automatically track and visualize YOLOv5 🚀 runs in Comet
TensorBoard: Start with 'tensorboard --logdir king_project', view at http://localhost:6006/
Overriding model.yaml nc=80 with nc=8
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 35061 models.yolo.Detect [8, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model summary: 214 layers, 7041205 parameters, 7041205 gradients, 16.0 GFLOPs
Transferred 343/349 items from yolov5s.pt
AMP: checks passed ✅
optimizer: SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 60 weight(decay=0.001), 60 bias
train: Scanning /home/jack/workspace/yolov5_practice/yolov5/king/train/labels.ca
val: Scanning /home/jack/workspace/yolov5_practice/yolov5/king/val/labels.cache.
AutoAnchor: 5.96 anchors/target, 1.000 Best Possible Recall (BPR). Current anchors are a good fit to dataset ✅
Plotting labels to king_project/yolov5s_size640_epochs20_batch128_small/labels.jpg...
Image sizes 640 train, 640 val
Using 1 dataloader workers
Logging results to king_project/yolov5s_size640_epochs20_batch128_small
Starting training for 20 epochs...
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
0/19 14.9G 0.1214 0.05881 0.06573 834 640: 1
Class Images Instances P R mAP50
all 52 265 0.00271 0.075 0.00911 0.00255
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
1/19 14.2G 0.1208 0.05827 0.06523 739 640: 1
Class Images Instances P R mAP50
all 52 265 0.00301 0.0997 0.00946 0.00202
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
2/19 23G 0.1185 0.06081 0.06443 795 640: 1
Class Images Instances P R mAP50
all 52 265 0.00279 0.0941 0.00938 0.00237
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
3/19 23G 0.1152 0.0621 0.06279 786 640: 1
Class Images Instances P R mAP50
all 52 265 0.00259 0.102 0.00868 0.00219
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
4/19 23G 0.1115 0.06555 0.06106 806 640: 1
Class Images Instances P R mAP50
all 52 265 0.00238 0.119 0.00738 0.00177
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
5/19 23G 0.1064 0.07103 0.05906 843 640: 1
Class Images Instances P R mAP50
all 52 265 0.00287 0.176 0.00739 0.00151
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
6/19 23G 0.1031 0.07249 0.05687 807 640: 1
Class Images Instances P R mAP50
all 52 265 0.00259 0.149 0.00914 0.00184
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
7/19 23G 0.09973 0.07334 0.05461 721 640: 1
Class Images Instances P R mAP50
all 52 265 0.00338 0.201 0.0088 0.00193
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
8/19 23G 0.09606 0.07647 0.05233 745 640: 1
Class Images Instances P R mAP50
all 52 265 0.00488 0.265 0.0103 0.00223
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
9/19 23G 0.0922 0.07684 0.04972 769 640: 1
Class Images Instances P R mAP50
all 52 265 0.511 0.0524 0.011 0.00247
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
10/19 23G 0.08839 0.07189 0.04755 674 640: 1
Class Images Instances P R mAP50
all 52 265 0.777 0.0607 0.0202 0.00496
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
11/19 23G 0.08644 0.07404 0.04512 774 640: 1
Class Images Instances P R mAP50
all 52 265 0.794 0.09 0.0467 0.0128
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
12/19 23G 0.08279 0.07256 0.04309 735 640: 1
Class Images Instances P R mAP50
all 52 265 0.795 0.106 0.0573 0.017
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
13/19 23G 0.0811 0.07099 0.04219 732 640: 1
Class Images Instances P R mAP50
all 52 265 0.806 0.113 0.0599 0.0167
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
14/19 23G 0.07985 0.07125 0.04135 761 640: 1
Class Images Instances P R mAP50
all 52 265 0.774 0.0839 0.0177 0.00438
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
15/19 23G 0.07824 0.06588 0.03995 721 640: 1
Class Images Instances P R mAP50
all 52 265 0.776 0.0949 0.0254 0.00614
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
16/19 23G 0.07685 0.06598 0.03842 695 640: 1
Class Images Instances P R mAP50
all 52 265 0.78 0.138 0.0474 0.0122
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
17/19 23G 0.07657 0.06825 0.03876 797 640: 1
Class Images Instances P R mAP50
all 52 265 0.793 0.12 0.052 0.014
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
18/19 23G 0.07623 0.07034 0.03819 793 640: 1
Class Images Instances P R mAP50
all 52 265 0.784 0.148 0.0619 0.0178
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
19/19 23G 0.07463 0.0664 0.03771 746 640: 1
Class Images Instances P R mAP50
all 52 265 0.797 0.138 0.0754 0.0229
20 epochs completed in 0.054 hours.
Optimizer stripped from king_project/yolov5s_size640_epochs20_batch128_small/weights/last.pt, 14.4MB
Optimizer stripped from king_project/yolov5s_size640_epochs20_batch128_small/weights/best.pt, 14.4MB
Validating king_project/yolov5s_size640_epochs20_batch128_small/weights/best.pt...
Fusing layers...
Model summary: 157 layers, 7031701 parameters, 0 gradients, 15.8 GFLOPs
Class Images Instances P R mAP50
all 52 265 0.797 0.138 0.0757 0.0228
hero 52 90 0.266 0.233 0.223 0.0609
dogface 52 91 0.109 0.868 0.351 0.113
monster 52 32 1 0 0.00492 0.00191
tower 52 18 1 0 0.00878 0.0036
grass 52 11 1 0 0.0041 0.000746
dragon 52 12 1 0 0.000483 4.83e-05
buff 52 1 1 0 0 0
blood 52 10 1 0 0.0138 0.00239
Results saved to king_project/yolov5s_size640_epochs20_batch128_small
根据最好权重,best.bt导出ONNX模型,设置batch=1(每次只推理一张图片), opset=11(兼容昇腾ATC转换模型)
# 导出模型为ONNX格式
cmd = f"cd {YOLOV5_DIR} && python export.py --weights {PROJECT}/{RUN_NAME}/weights/best.pt --include onnx --img 640 --batch 1 --opset=11"
!{cmd}export: data=data/coco128.yaml, weights=['vehicles_open_image_project/yolov5s_size640_epochs20_batch32_small/weights/best.pt'], imgsz=[640], batch_size=1, device=cpu, half=False, inplace=False, keras=False, optimize=False, int8=False, per_tensor=False, dynamic=False, simplify=False, opset=11, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx']
YOLOv5 🚀 v7.0-342-g12be4996 Python-3.10.14 torch-2.2.1 CPU
Fusing layers...
Model summary: 157 layers, 7031701 parameters, 0 gradients, 15.8 GFLOPs
PyTorch: starting from vehicles_open_image_project/yolov5s_size640_epochs20_batch32_small/weights/best.pt with output shape (1, 25200, 13) (13.7 MB)
ONNX: starting export with onnx 1.16.1...
ONNX: export success ✅ 0.5s, saved as vehicles_open_image_project/yolov5s_size640_epochs20_batch32_small/weights/best.onnx (27.3 MB)
Export complete (0.7s)
Results saved to /home/jack/workspace/yolov5_practice/yolov5/vehicles_open_image_project/yolov5s_size640_epochs20_batch32_small/weights
Detect: python detect.py --weights vehicles_open_image_project/yolov5s_size640_epochs20_batch32_small/weights/best.onnx
Validate: python val.py --weights vehicles_open_image_project/yolov5s_size640_epochs20_batch32_small/weights/best.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'vehicles_open_image_project/yolov5s_size640_epochs20_batch32_small/weights/best.onnx')
Visualize: https://netron.app
通过冻结层训练YOLOv5模型¶
在目标检测中,通常会在MS COCO数据集上预训练的模型,并在垂直领域数据集上对其进行微调。大多数时候,需要训练模型的所有层,因为对象检测是一个具有挑战性的问题,需要解决数据集变化较大的问题。
但对于特定领域,我们并不总是需要训练整个模型,可以通过冻结某些预训练模型层并训练其他层来获得几乎相同的结果。通常情况下冻结某些层并不是很容易的操作。需要修改源代码来完成。
Ultralytics YOLOv5支持冻结模型某些层并训练的机制。我们只需要在执行train.py时使用--freeze设置冻结层。
SIZE = 640
BATCH_SIZE = 128
EPOCHS = 25
MODEL = "yolov5s"
WORKERS = 1
PROJECT = "king_project"
RUN_NAME = f"{MODEL}_size{SIZE}_epochs{EPOCHS}_batch{BATCH_SIZE}_small"# 从yolov5目录运行冻结层训练,冻结前22个模块(0-21),仅保留最后3个模块(22-24)可训练。
freeze_layers = ' '.join([str(i) for i in range(22)])
cmd = f"cd {YOLOV5_DIR} && python train.py --img {SIZE} --batch {BATCH_SIZE} --epochs {EPOCHS} --data king/data.yaml --weights {MODEL}.pt --workers {WORKERS} --project {PROJECT} --name {RUN_NAME} --exist-ok --freeze {freeze_layers}"
print(f"Running: {cmd}")
!{cmd}Running: cd ../../../yolov5 && python train.py --img 640 --batch 128 --epochs 25 --data king/data.yaml --weights yolov5s.pt --workers 1 --project king_project --name yolov5s_size640_epochs25_batch128_small --exist-ok --freeze 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
/home/jack/workspace/computer_vision_class_en/yolov5/utils/general.py:32: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
import pkg_resources as pkg
train: weights=yolov5s.pt, cfg=, data=king/data.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=25, batch_size=128, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, evolve_population=data/hyps, resume_evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=1, project=king_project, name=yolov5s_size640_epochs25_batch128_small, exist_ok=True, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21], save_period=-1, seed=0, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest, ndjson_console=False, ndjson_file=False
github: ⚠️ YOLOv5 is out of date by 111 commits. Use 'git pull' or 'git clone https://github.com/ultralytics/yolov5' to update.
YOLOv5 🚀 v7.0-342-g12be4996 Python-3.10.14 torch-2.2.1 CUDA:0 (NVIDIA GeForce RTX 3090 Ti, 24110MiB)
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Comet: run 'pip install comet_ml' to automatically track and visualize YOLOv5 🚀 runs in Comet
TensorBoard: Start with 'tensorboard --logdir king_project', view at http://localhost:6006/
Overriding model.yaml nc=80 with nc=8
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 35061 models.yolo.Detect [8, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model summary: 214 layers, 7041205 parameters, 7041205 gradients, 16.0 GFLOPs
Transferred 343/349 items from yolov5s.pt
AMP: checks passed ✅
freezing model.0.conv.weight
freezing model.0.bn.weight
freezing model.0.bn.bias
freezing model.1.conv.weight
freezing model.1.bn.weight
freezing model.1.bn.bias
freezing model.2.cv1.conv.weight
freezing model.2.cv1.bn.weight
freezing model.2.cv1.bn.bias
freezing model.2.cv2.conv.weight
freezing model.2.cv2.bn.weight
freezing model.2.cv2.bn.bias
freezing model.2.cv3.conv.weight
freezing model.2.cv3.bn.weight
freezing model.2.cv3.bn.bias
freezing model.2.m.0.cv1.conv.weight
freezing model.2.m.0.cv1.bn.weight
freezing model.2.m.0.cv1.bn.bias
freezing model.2.m.0.cv2.conv.weight
freezing model.2.m.0.cv2.bn.weight
freezing model.2.m.0.cv2.bn.bias
freezing model.3.conv.weight
freezing model.3.bn.weight
freezing model.3.bn.bias
freezing model.4.cv1.conv.weight
freezing model.4.cv1.bn.weight
freezing model.4.cv1.bn.bias
freezing model.4.cv2.conv.weight
freezing model.4.cv2.bn.weight
freezing model.4.cv2.bn.bias
freezing model.4.cv3.conv.weight
freezing model.4.cv3.bn.weight
freezing model.4.cv3.bn.bias
freezing model.4.m.0.cv1.conv.weight
freezing model.4.m.0.cv1.bn.weight
freezing model.4.m.0.cv1.bn.bias
freezing model.4.m.0.cv2.conv.weight
freezing model.4.m.0.cv2.bn.weight
freezing model.4.m.0.cv2.bn.bias
freezing model.4.m.1.cv1.conv.weight
freezing model.4.m.1.cv1.bn.weight
freezing model.4.m.1.cv1.bn.bias
freezing model.4.m.1.cv2.conv.weight
freezing model.4.m.1.cv2.bn.weight
freezing model.4.m.1.cv2.bn.bias
freezing model.5.conv.weight
freezing model.5.bn.weight
freezing model.5.bn.bias
freezing model.6.cv1.conv.weight
freezing model.6.cv1.bn.weight
freezing model.6.cv1.bn.bias
freezing model.6.cv2.conv.weight
freezing model.6.cv2.bn.weight
freezing model.6.cv2.bn.bias
freezing model.6.cv3.conv.weight
freezing model.6.cv3.bn.weight
freezing model.6.cv3.bn.bias
freezing model.6.m.0.cv1.conv.weight
freezing model.6.m.0.cv1.bn.weight
freezing model.6.m.0.cv1.bn.bias
freezing model.6.m.0.cv2.conv.weight
freezing model.6.m.0.cv2.bn.weight
freezing model.6.m.0.cv2.bn.bias
freezing model.6.m.1.cv1.conv.weight
freezing model.6.m.1.cv1.bn.weight
freezing model.6.m.1.cv1.bn.bias
freezing model.6.m.1.cv2.conv.weight
freezing model.6.m.1.cv2.bn.weight
freezing model.6.m.1.cv2.bn.bias
freezing model.6.m.2.cv1.conv.weight
freezing model.6.m.2.cv1.bn.weight
freezing model.6.m.2.cv1.bn.bias
freezing model.6.m.2.cv2.conv.weight
freezing model.6.m.2.cv2.bn.weight
freezing model.6.m.2.cv2.bn.bias
freezing model.7.conv.weight
freezing model.7.bn.weight
freezing model.7.bn.bias
freezing model.8.cv1.conv.weight
freezing model.8.cv1.bn.weight
freezing model.8.cv1.bn.bias
freezing model.8.cv2.conv.weight
freezing model.8.cv2.bn.weight
freezing model.8.cv2.bn.bias
freezing model.8.cv3.conv.weight
freezing model.8.cv3.bn.weight
freezing model.8.cv3.bn.bias
freezing model.8.m.0.cv1.conv.weight
freezing model.8.m.0.cv1.bn.weight
freezing model.8.m.0.cv1.bn.bias
freezing model.8.m.0.cv2.conv.weight
freezing model.8.m.0.cv2.bn.weight
freezing model.8.m.0.cv2.bn.bias
freezing model.9.cv1.conv.weight
freezing model.9.cv1.bn.weight
freezing model.9.cv1.bn.bias
freezing model.9.cv2.conv.weight
freezing model.9.cv2.bn.weight
freezing model.9.cv2.bn.bias
freezing model.10.conv.weight
freezing model.10.bn.weight
freezing model.10.bn.bias
freezing model.13.cv1.conv.weight
freezing model.13.cv1.bn.weight
freezing model.13.cv1.bn.bias
freezing model.13.cv2.conv.weight
freezing model.13.cv2.bn.weight
freezing model.13.cv2.bn.bias
freezing model.13.cv3.conv.weight
freezing model.13.cv3.bn.weight
freezing model.13.cv3.bn.bias
freezing model.13.m.0.cv1.conv.weight
freezing model.13.m.0.cv1.bn.weight
freezing model.13.m.0.cv1.bn.bias
freezing model.13.m.0.cv2.conv.weight
freezing model.13.m.0.cv2.bn.weight
freezing model.13.m.0.cv2.bn.bias
freezing model.14.conv.weight
freezing model.14.bn.weight
freezing model.14.bn.bias
freezing model.17.cv1.conv.weight
freezing model.17.cv1.bn.weight
freezing model.17.cv1.bn.bias
freezing model.17.cv2.conv.weight
freezing model.17.cv2.bn.weight
freezing model.17.cv2.bn.bias
freezing model.17.cv3.conv.weight
freezing model.17.cv3.bn.weight
freezing model.17.cv3.bn.bias
freezing model.17.m.0.cv1.conv.weight
freezing model.17.m.0.cv1.bn.weight
freezing model.17.m.0.cv1.bn.bias
freezing model.17.m.0.cv2.conv.weight
freezing model.17.m.0.cv2.bn.weight
freezing model.17.m.0.cv2.bn.bias
freezing model.18.conv.weight
freezing model.18.bn.weight
freezing model.18.bn.bias
freezing model.20.cv1.conv.weight
freezing model.20.cv1.bn.weight
freezing model.20.cv1.bn.bias
freezing model.20.cv2.conv.weight
freezing model.20.cv2.bn.weight
freezing model.20.cv2.bn.bias
freezing model.20.cv3.conv.weight
freezing model.20.cv3.bn.weight
freezing model.20.cv3.bn.bias
freezing model.20.m.0.cv1.conv.weight
freezing model.20.m.0.cv1.bn.weight
freezing model.20.m.0.cv1.bn.bias
freezing model.20.m.0.cv2.conv.weight
freezing model.20.m.0.cv2.bn.weight
freezing model.20.m.0.cv2.bn.bias
freezing model.21.conv.weight
freezing model.21.bn.weight
freezing model.21.bn.bias
optimizer: SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 60 weight(decay=0.001), 60 bias
train: Scanning /home/jack/workspace/yolov5_practice/yolov5/king/train/labels.ca
val: Scanning /home/jack/workspace/yolov5_practice/yolov5/king/val/labels.cache.
AutoAnchor: 5.96 anchors/target, 1.000 Best Possible Recall (BPR). Current anchors are a good fit to dataset ✅
Plotting labels to king_project/yolov5s_size640_epochs25_batch128_small/labels.jpg...
Image sizes 640 train, 640 val
Using 1 dataloader workers
Logging results to king_project/yolov5s_size640_epochs25_batch128_small
Starting training for 25 epochs...
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
0/24 4.59G 0.1214 0.05881 0.06573 834 640: 1
Class Images Instances P R mAP50
all 52 265 0.00277 0.0764 0.00929 0.00258
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
1/24 5.86G 0.1207 0.05824 0.06525 739 640: 1
Class Images Instances P R mAP50
all 52 265 0.00296 0.105 0.00932 0.00268
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
2/24 5.86G 0.1185 0.06055 0.06463 795 640: 1
Class Images Instances P R mAP50
all 52 265 0.00252 0.0925 0.00827 0.00196
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
3/24 5.86G 0.1155 0.06144 0.06321 786 640: 1
Class Images Instances P R mAP50
all 52 265 0.00239 0.0991 0.00863 0.00204
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
4/24 5.86G 0.1125 0.0643 0.06192 806 640: 1
Class Images Instances P R mAP50
all 52 265 0.00266 0.13 0.00887 0.00245
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
5/24 5.86G 0.1081 0.06938 0.06011 843 640: 1
Class Images Instances P R mAP50
all 52 265 0.00271 0.149 0.00531 0.00148
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
6/24 5.86G 0.1059 0.07002 0.05827 807 640: 1
Class Images Instances P R mAP50
all 52 265 0.00304 0.18 0.00576 0.00157
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
7/24 5.86G 0.1039 0.07034 0.05652 721 640: 1
Class Images Instances P R mAP50
all 52 265 0.00364 0.225 0.00745 0.00212
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
8/24 5.86G 0.1018 0.07296 0.05471 745 640: 1
Class Images Instances P R mAP50
all 52 265 0.384 0.0496 0.0128 0.00337
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
9/24 5.86G 0.09989 0.07348 0.05307 769 640: 1
Class Images Instances P R mAP50
all 52 265 0.765 0.0525 0.0151 0.00377
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
10/24 5.86G 0.09812 0.06958 0.05206 674 640: 1
Class Images Instances P R mAP50
all 52 265 0.777 0.0331 0.018 0.00523
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
11/24 5.86G 0.09795 0.07373 0.05047 774 640: 1
Class Images Instances P R mAP50
all 52 265 0.784 0.0316 0.0211 0.0052
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
12/24 5.86G 0.09546 0.07452 0.04903 735 640: 1
Class Images Instances P R mAP50
all 52 265 0.788 0.0399 0.0346 0.00869
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
13/24 5.86G 0.09487 0.07432 0.04838 732 640: 1
Class Images Instances P R mAP50
all 52 265 0.802 0.0412 0.038 0.0103
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
14/24 5.86G 0.09425 0.07562 0.04737 761 640: 1
Class Images Instances P R mAP50
all 52 265 0.814 0.0454 0.0438 0.0111
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
15/24 5.86G 0.09345 0.06988 0.04596 721 640: 1
Class Images Instances P R mAP50
all 52 265 0.79 0.062 0.0392 0.0107
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
16/24 5.86G 0.09257 0.0706 0.04468 695 640: 1
Class Images Instances P R mAP50
all 52 265 0.797 0.0661 0.0451 0.0106
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
17/24 5.86G 0.09392 0.07396 0.04494 797 640: 1
Class Images Instances P R mAP50
all 52 265 0.812 0.0744 0.0565 0.0144
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
18/24 5.86G 0.09323 0.07748 0.04433 793 640: 1
Class Images Instances P R mAP50
all 52 265 0.815 0.0716 0.0627 0.0188
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
19/24 5.86G 0.09201 0.0728 0.0436 746 640: 1
Class Images Instances P R mAP50
all 52 265 0.822 0.062 0.0627 0.0191
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
20/24 5.86G 0.09147 0.07638 0.04332 801 640: 1
Class Images Instances P R mAP50
all 52 265 0.827 0.064 0.069 0.0229
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
21/24 5.86G 0.09039 0.07306 0.04279 741 640: 1
Class Images Instances P R mAP50
all 52 265 0.819 0.0774 0.0757 0.026
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
22/24 5.86G 0.09074 0.07097 0.04322 767 640: 1
Class Images Instances P R mAP50
all 52 265 0.824 0.077 0.0774 0.0256
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
23/24 5.86G 0.0914 0.0764 0.04279 862 640: 1
Class Images Instances P R mAP50
all 52 265 0.816 0.0703 0.0755 0.0262
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
24/24 5.86G 0.09044 0.07175 0.04244 702 640: 1
Class Images Instances P R mAP50
all 52 265 0.817 0.0717 0.0791 0.028
25 epochs completed in 0.068 hours.
Optimizer stripped from king_project/yolov5s_size640_epochs25_batch128_small/weights/last.pt, 14.4MB
Optimizer stripped from king_project/yolov5s_size640_epochs25_batch128_small/weights/best.pt, 14.4MB
Validating king_project/yolov5s_size640_epochs25_batch128_small/weights/best.pt...
Fusing layers...
Model summary: 157 layers, 7031701 parameters, 0 gradients, 15.8 GFLOPs
Class Images Instances P R mAP50
all 52 265 0.817 0.0717 0.0793 0.0282
hero 52 90 0.316 0.178 0.165 0.0395
dogface 52 91 0.222 0.396 0.258 0.0804
monster 52 32 1 0 0.00808 0.00166
tower 52 18 1 0 0.0669 0.0256
grass 52 11 1 0 0.127 0.0746
dragon 52 12 1 0 0 0
buff 52 1 1 0 0 0
blood 52 10 1 0 0.00904 0.00415
Results saved to king_project/yolov5s_size640_epochs25_batch128_small
# 导出冻结训练模型为ONNX格式
cmd = f"cd {YOLOV5_DIR} && python export.py --weights {PROJECT}/{RUN_NAME}/weights/best.pt --include onnx --img 640 --batch 1 --opset=11"
!{cmd}/home/jack/workspace/computer_vision_class_en/yolov5/utils/general.py:32: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
import pkg_resources as pkg
export: data=data/coco128.yaml, weights=['king_project/yolov5s_size640_epochs25_batch128_small/weights/best.pt'], imgsz=[640], batch_size=1, device=cpu, half=False, inplace=False, keras=False, optimize=False, int8=False, per_tensor=False, dynamic=False, simplify=False, opset=11, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx']
YOLOv5 🚀 v7.0-342-g12be4996 Python-3.10.14 torch-2.2.1 CPU
Fusing layers...
Model summary: 157 layers, 7031701 parameters, 0 gradients, 15.8 GFLOPs
PyTorch: starting from king_project/yolov5s_size640_epochs25_batch128_small/weights/best.pt with output shape (1, 25200, 13) (13.7 MB)
ONNX: starting export with onnx 1.16.1...
ONNX: export success ✅ 0.5s, saved as king_project/yolov5s_size640_epochs25_batch128_small/weights/best.onnx (27.3 MB)
Export complete (0.7s)
Results saved to /home/jack/workspace/computer_vision_class_en/yolov5/king_project/yolov5s_size640_epochs25_batch128_small/weights
Detect: python detect.py --weights king_project/yolov5s_size640_epochs25_batch128_small/weights/best.onnx
Validate: python val.py --weights king_project/yolov5s_size640_epochs25_batch128_small/weights/best.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'king_project/yolov5s_size640_epochs25_batch128_small/weights/best.onnx')
Visualize: https://netron.app
训练结果可视化¶
训练完成后,YOLOv5会自动生成多种可视化结果,帮助我们分析模型性能。下面我们来查看这些结果。
# 定义结果路径
import os
from IPython.display import Image, display
# 定义训练参数(与训练时保持一致)
SIZE = 640
BATCH_SIZE = 128
EPOCHS = 25
MODEL = "yolov5s"
PROJECT = "king_project"
RUN_NAME = f"{MODEL}_size{SIZE}_epochs{EPOCHS}_batch{BATCH_SIZE}_small"
# YOLOv5目录的相对路径
RESULTS_DIR = f"{YOLOV5_DIR}/{PROJECT}/{RUN_NAME}"
print(f"Results directory: {RESULTS_DIR}")
print(f"\nAvailable files:")
for f in sorted(os.listdir(RESULTS_DIR)):
print(f" - {f}")Results directory: ../../../yolov5/king_project/yolov5s_size640_epochs25_batch128_small
Available files:
- F1_curve.png
- PR_curve.png
- P_curve.png
- R_curve.png
- confusion_matrix.png
- events.out.tfevents.1766490044.jack-B460HD3.1336333.0
- hyp.yaml
- labels.jpg
- labels_correlogram.jpg
- opt.yaml
- results.csv
- results.png
- train_batch0.jpg
- train_batch1.jpg
- train_batch2.jpg
- val_batch0_labels.jpg
- val_batch0_pred.jpg
- weights
训练曲线¶
下图展示了训练过程中的各项指标变化,包括:
Box Loss: 边界框回归损失
Objectness Loss: 目标置信度损失
Classification Loss: 分类损失
Precision/Recall: 精确率和召回率
mAP: 平均精度
# 显示训练曲线
display(Image(filename=f"{RESULTS_DIR}/results.png", width=800))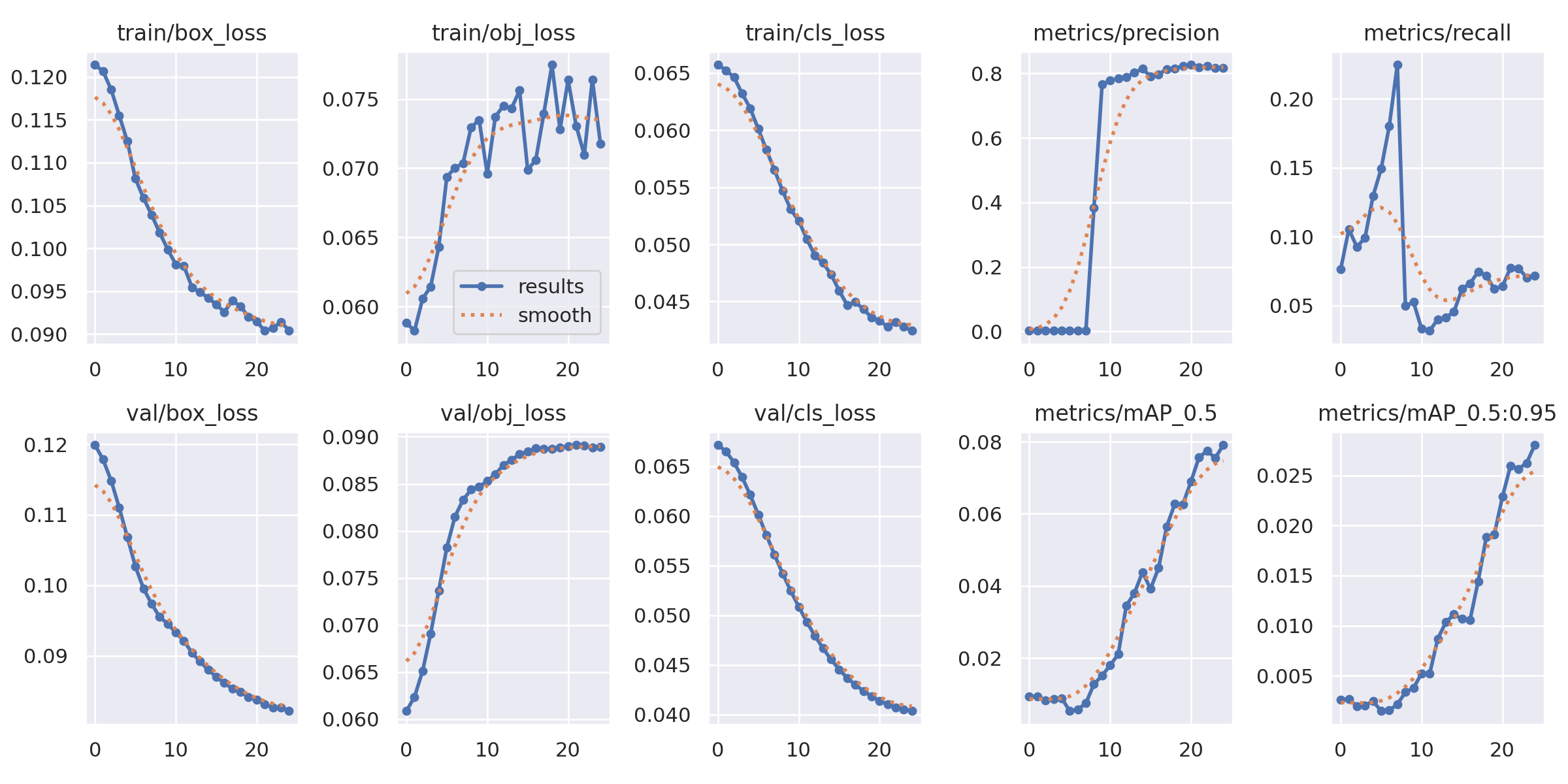
混淆矩阵¶
混淆矩阵展示了模型在各个类别上的预测情况,对角线上的值越高表示该类别的识别准确率越高。
# 显示混淆矩阵
display(Image(filename=f"{RESULTS_DIR}/confusion_matrix.png", width=600))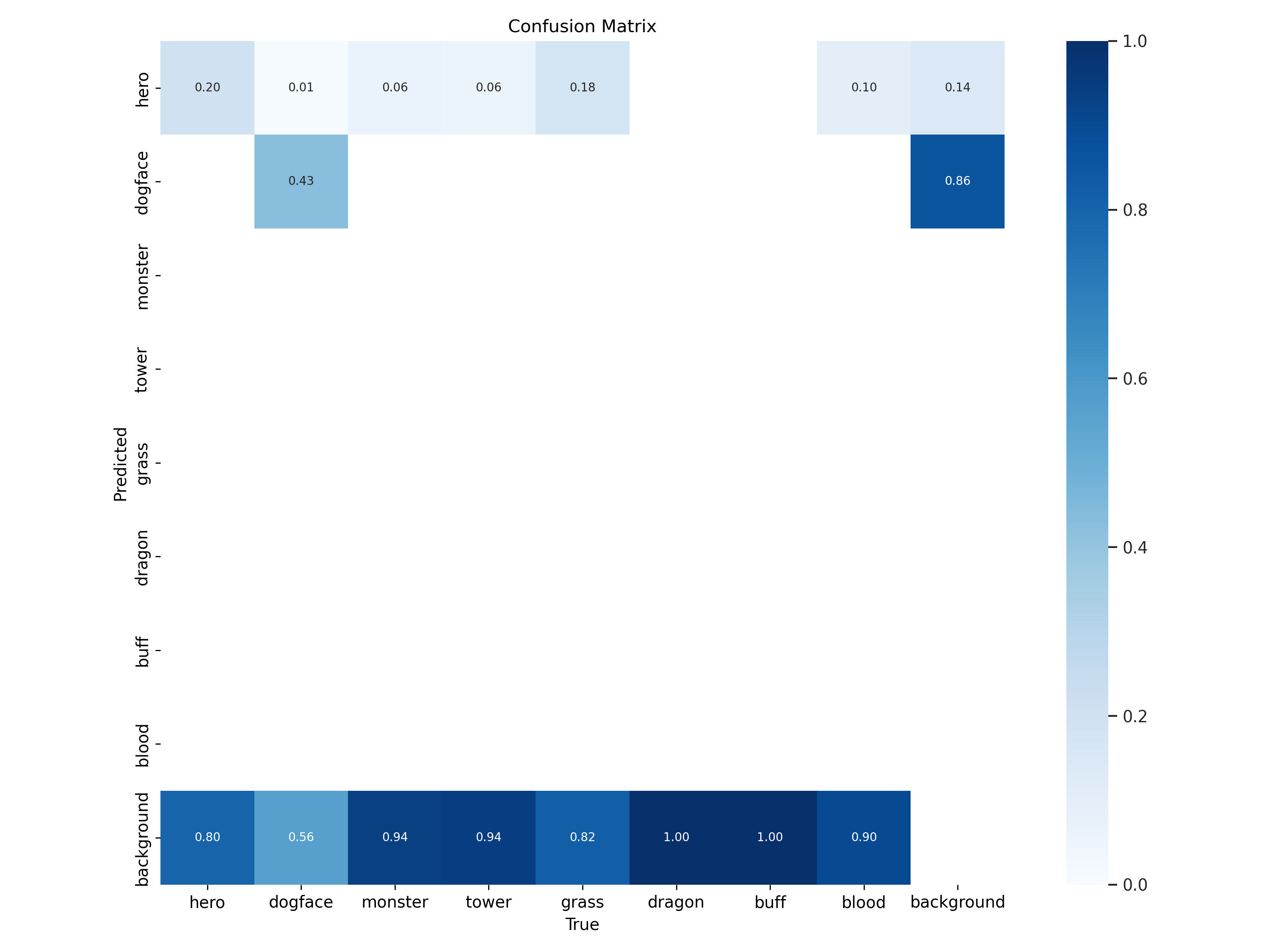
精确率-召回率曲线¶
PR曲线展示了不同置信度阈值下精确率和召回率的权衡关系。曲线下的面积(AUC)越大,模型性能越好。
# 显示PR曲线
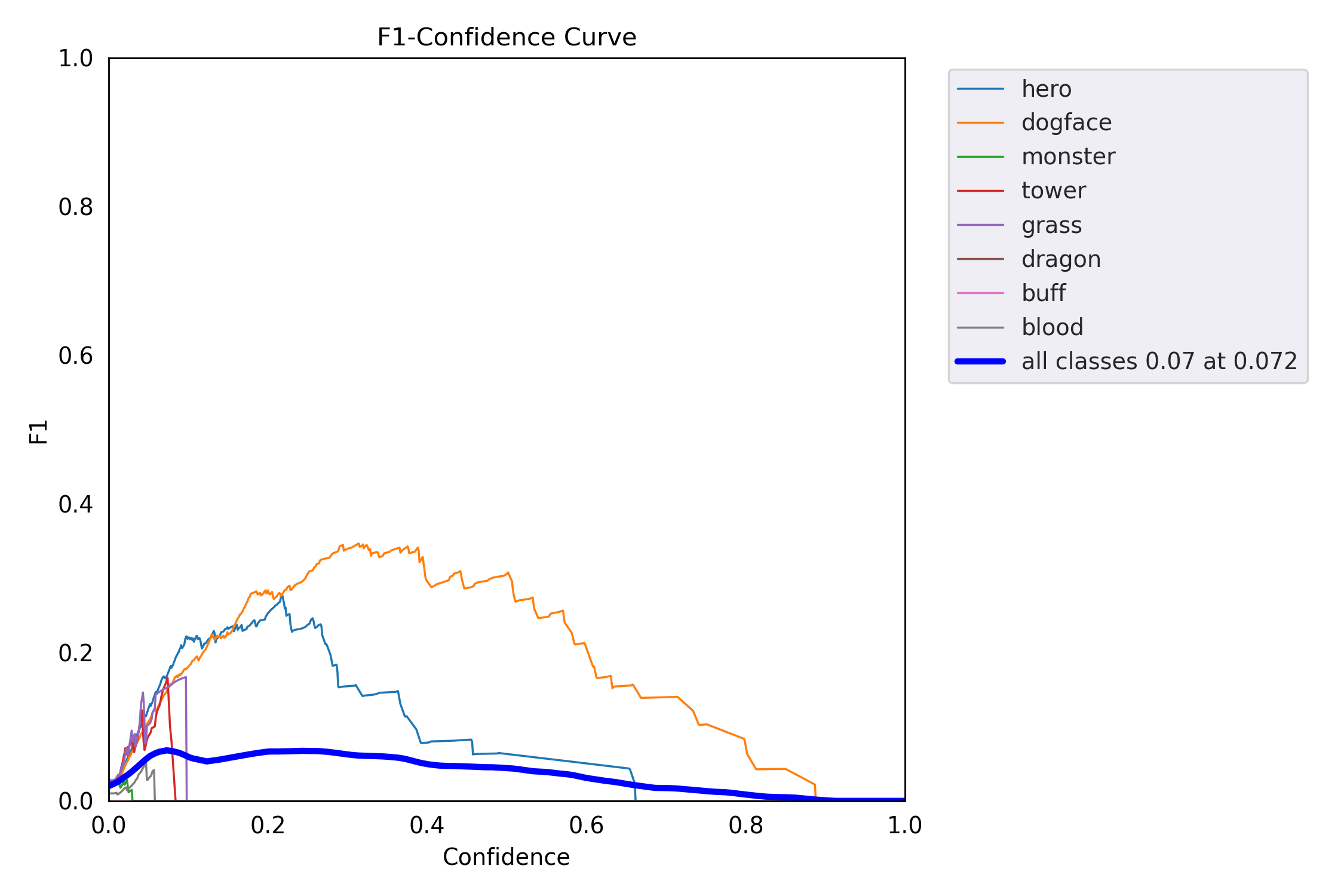
display(Image(filename=f"{RESULTS_DIR}/PR_curve.png", width=400))
display(Image(filename=f"{RESULTS_DIR}/F1_curve.png", width=400))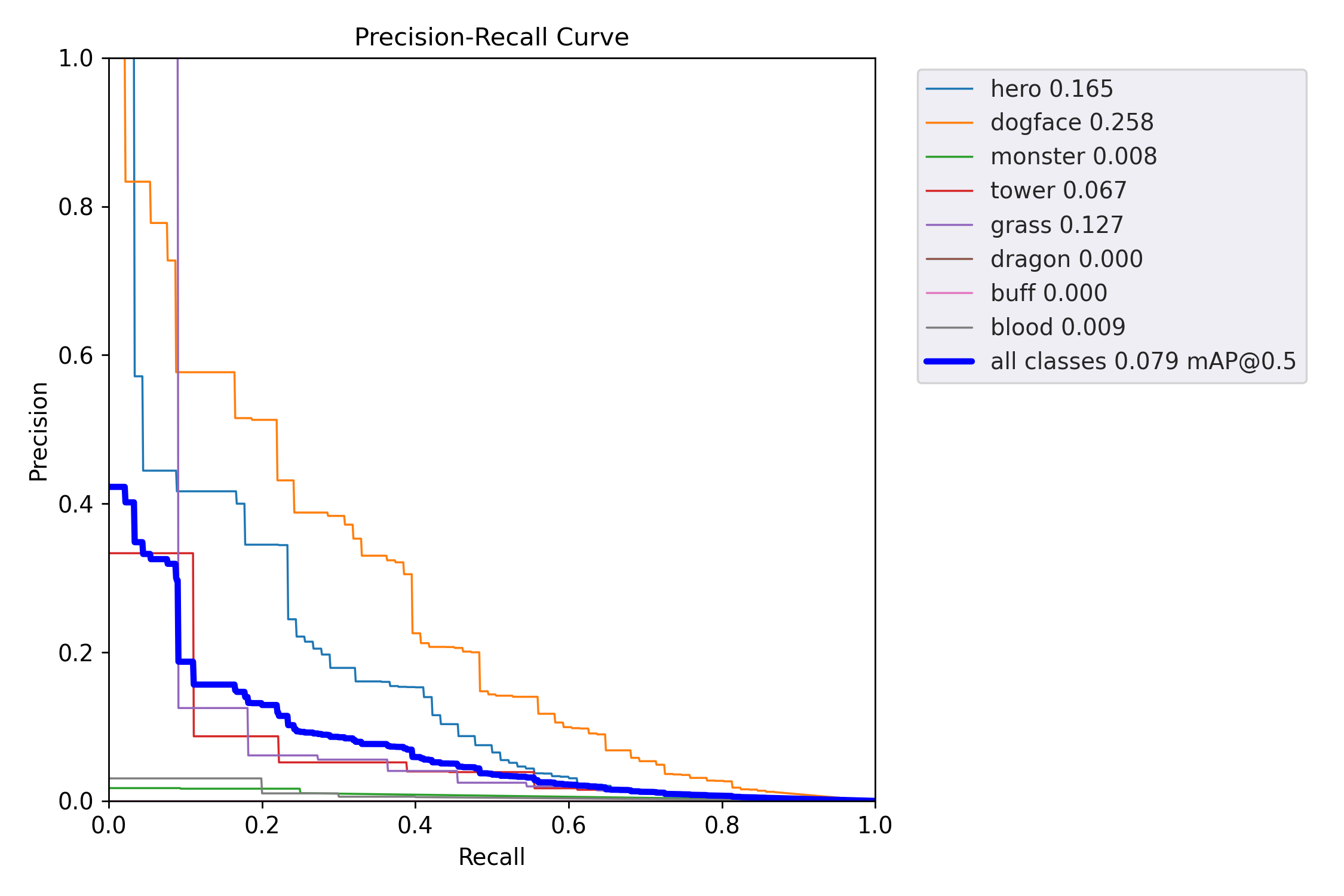
验证集预测结果¶
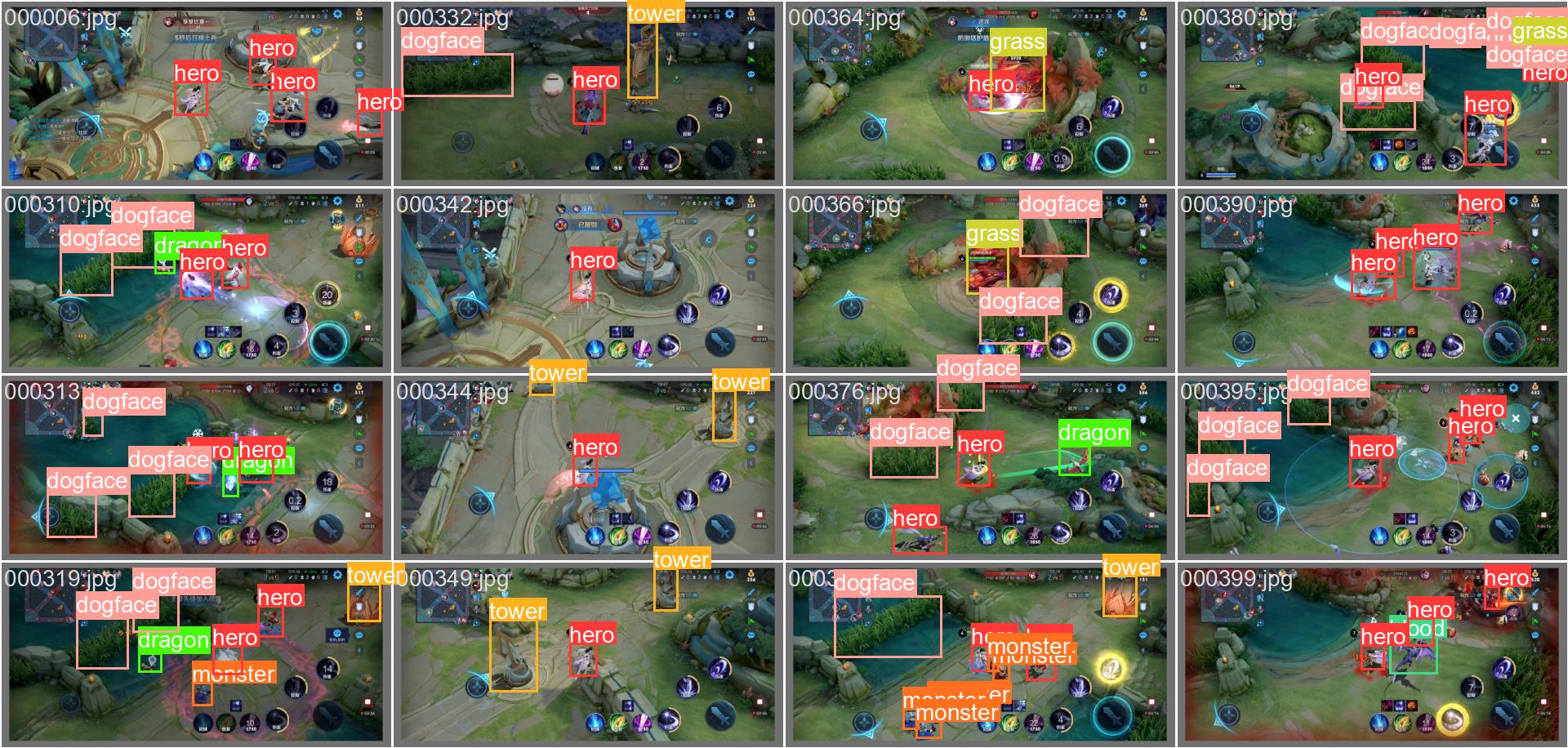
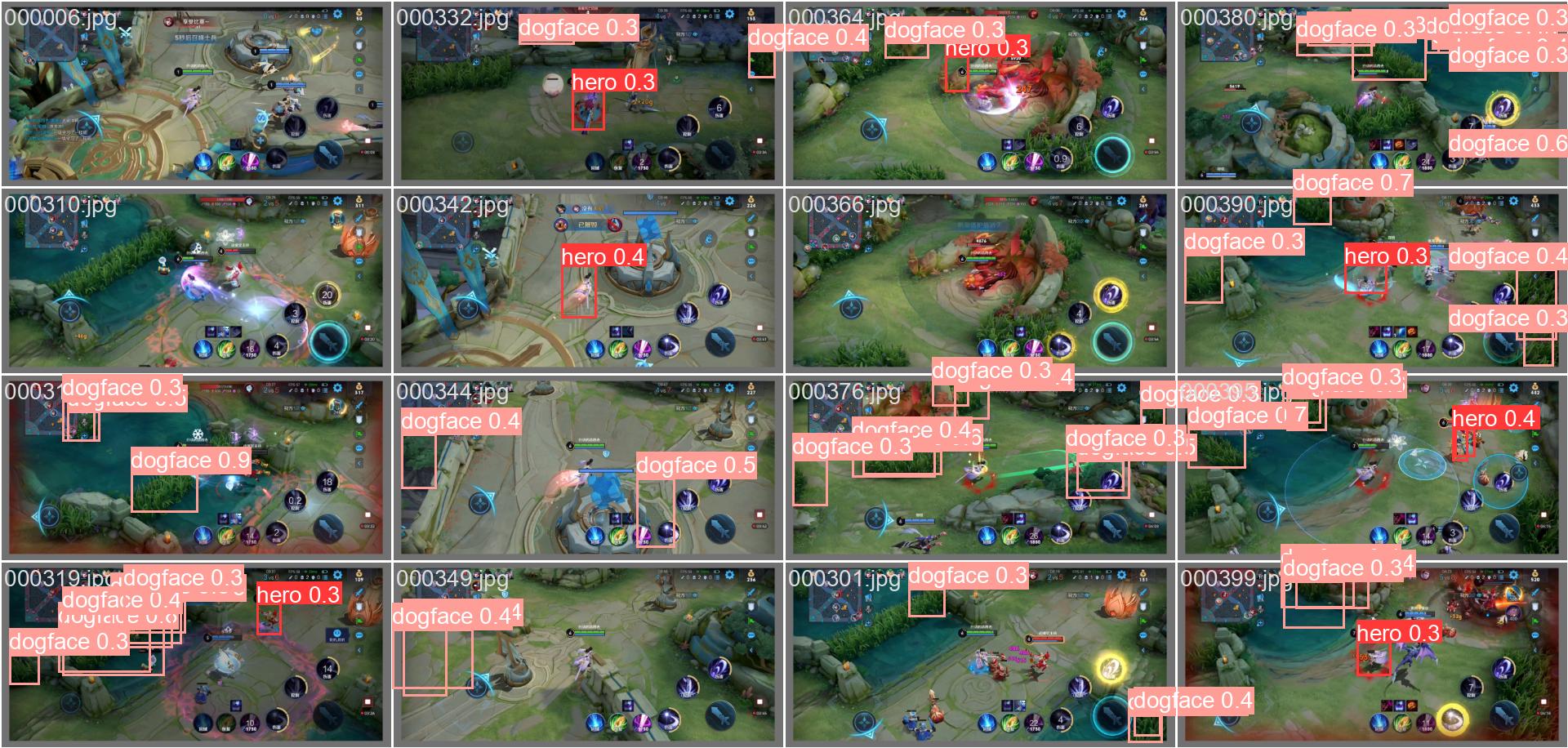
下图对比了验证集上的真实标注(左)和模型预测结果(右)。
# 显示验证集预测对比
print("Ground Truth Labels:")
display(Image(filename=f"{RESULTS_DIR}/val_batch0_labels.jpg", width=700))
print("\nModel Predictions:")
display(Image(filename=f"{RESULTS_DIR}/val_batch0_pred.jpg", width=700))Ground Truth Labels:
Model Predictions:
模型推理¶
使用训练好的模型对新图像进行目标检测推理。YOLOv5提供了detect.py脚本,可以方便地对图像、视频或摄像头进行检测。
# 使用训练好的模型进行推理
# 切换到yolov5目录执行detect.py
cmd = f"cd {YOLOV5_DIR} && python detect.py --weights {PROJECT}/{RUN_NAME}/weights/best.pt --source king/val/images --img {SIZE} --conf-thres 0.25 --project {PROJECT} --name inference_results --exist-ok"
print(f"Running: {cmd}")
!{cmd}Running: cd ../../../yolov5 && python detect.py --weights king_project/yolov5s_size640_epochs25_batch128_small/weights/best.pt --source king/val/images --img 640 --conf-thres 0.25 --project king_project --name inference_results --exist-ok
/home/jack/workspace/computer_vision_class_en/yolov5/utils/general.py:32: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
import pkg_resources as pkg
detect: weights=['king_project/yolov5s_size640_epochs25_batch128_small/weights/best.pt'], source=king/val/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_csv=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=king_project, name=inference_results, exist_ok=True, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 🚀 v7.0-342-g12be4996 Python-3.10.14 torch-2.2.1 CUDA:0 (NVIDIA GeForce RTX 3090 Ti, 24110MiB)
Fusing layers...
Model summary: 157 layers, 7031701 parameters, 0 gradients, 15.8 GFLOPs
image 1/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000006.jpg: 320x640 1 hero, 59.3ms
image 2/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000007.jpg: 320x640 1 hero, 1 dogface, 4.6ms
image 3/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000015.jpg: 320x640 (no detections), 4.6ms
image 4/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000020.jpg: 320x640 3 heros, 1 dogface, 5.0ms
image 5/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000022.jpg: 320x640 1 hero, 1 dogface, 4.6ms
image 6/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000031.jpg: 320x640 2 dogfaces, 4.6ms
image 7/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000044.jpg: 320x640 2 dogfaces, 4.6ms
image 8/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000077.jpg: 320x640 3 dogfaces, 4.6ms
image 9/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000098.jpg: 320x640 1 hero, 1 dogface, 4.6ms
image 10/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000113.jpg: 320x640 2 heros, 1 dogface, 4.5ms
image 11/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000115.jpg: 320x640 (no detections), 4.6ms
image 12/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000130.jpg: 320x640 2 heros, 4.9ms
image 13/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000156.jpg: 320x640 3 dogfaces, 4.6ms
image 14/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000162.jpg: 320x640 4 dogfaces, 4.6ms
image 15/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000167.jpg: 320x640 1 hero, 4.5ms
image 16/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000179.jpg: 320x640 2 heros, 2 dogfaces, 4.5ms
image 17/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000192.jpg: 320x640 3 heros, 4.6ms
image 18/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000215.jpg: 320x640 2 heros, 4 dogfaces, 4.5ms
image 19/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000216.jpg: 320x640 2 dogfaces, 4.5ms
image 20/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000236.jpg: 320x640 2 heros, 4 dogfaces, 4.6ms
image 21/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000251.jpg: 320x640 1 hero, 3 dogfaces, 4.6ms
image 22/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000253.jpg: 320x640 1 hero, 3 dogfaces, 4.5ms
image 23/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000254.jpg: 320x640 3 dogfaces, 4.8ms
image 24/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000263.jpg: 320x640 1 dogface, 4.7ms
image 25/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000281.jpg: 320x640 6 dogfaces, 4.7ms
image 26/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000295.jpg: 320x640 1 hero, 4 dogfaces, 4.7ms
image 27/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000297.jpg: 320x640 2 heros, 1 dogface, 4.6ms
image 28/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000301.jpg: 320x640 1 hero, 2 dogfaces, 4.5ms
image 29/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000310.jpg: 320x640 (no detections), 4.6ms
image 30/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000313.jpg: 320x640 5 dogfaces, 4.6ms
image 31/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000319.jpg: 320x640 1 hero, 3 dogfaces, 4.5ms
image 32/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000332.jpg: 320x640 1 hero, 5 dogfaces, 4.6ms
image 33/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000342.jpg: 320x640 2 heros, 4.6ms
image 34/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000344.jpg: 320x640 1 dogface, 4.5ms
image 35/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000349.jpg: 320x640 2 heros, 4.6ms
image 36/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000364.jpg: 320x640 1 dogface, 4.6ms
image 37/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000366.jpg: 320x640 5 dogfaces, 4.6ms
image 38/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000376.jpg: 320x640 1 hero, 5 dogfaces, 4.6ms
image 39/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000380.jpg: 320x640 1 hero, 2 dogfaces, 4.5ms
image 40/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000384.jpg: 320x640 3 heros, 3 dogfaces, 4.6ms
image 41/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000390.jpg: 320x640 1 hero, 3 dogfaces, 4.5ms
image 42/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000395.jpg: 320x640 1 hero, 4 dogfaces, 4.5ms
image 43/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000399.jpg: 320x640 1 hero, 1 dogface, 4.6ms
image 44/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000426.jpg: 320x640 5 dogfaces, 4.6ms
image 45/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000431.jpg: 320x640 2 heros, 4 dogfaces, 4.5ms
image 46/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000436.jpg: 320x640 3 dogfaces, 4.6ms
image 47/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000783.jpg: 320x640 1 hero, 3 dogfaces, 4.6ms
image 48/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000843.jpg: 320x640 4 dogfaces, 4.5ms
image 49/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000845.jpg: 320x640 2 heros, 2 dogfaces, 4.5ms
image 50/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/000942.jpg: 320x640 2 heros, 1 dogface, 4.6ms
image 51/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/001061.jpg: 320x640 (no detections), 4.5ms
image 52/52 /home/jack/workspace/computer_vision_class_en/yolov5/king/val/images/001244.jpg: 320x640 5 dogfaces, 4.6ms
Speed: 0.2ms pre-process, 5.6ms inference, 2.1ms NMS per image at shape (1, 3, 640, 640)
Results saved to king_project/inference_results
推理结果展示¶
下面展示模型在验证集图像上的检测结果:
# 显示推理结果
import glob
inference_dir = f"{YOLOV5_DIR}/{PROJECT}/inference_results"
result_images = sorted(glob.glob(f"{inference_dir}/*.jpg"))[:6]
print(f"Found {len(glob.glob(f'{inference_dir}/*.jpg'))} inference results")
print(f"\nDisplaying first {len(result_images)} images:")
for img_path in result_images:
print(f"\n{os.path.basename(img_path)}:")
display(Image(filename=img_path, width=500))Found 52 inference results
Displaying first 6 images:
000006.jpg:
000007.jpg:
000015.jpg:
000020.jpg:
000022.jpg:
000031.jpg:
总结¶
本实验完成了以下内容:
数据准备:下载并配置王者数据集,了解YOLOv5的标注格式
模型训练:使用YOLOv5s在自定义数据集上训练目标检测器
冻结层训练:演示了如何冻结backbone层进行微调
模型导出:将训练好的模型导出为ONNX格式
结果可视化:分析训练曲线、混淆矩阵和PR曲线
模型推理:使用训练好的模型对新图像进行检测
后续改进方向:
增加训练数据量
调整数据增强策略
尝试更大的模型(如YOLOv5m、YOLOv5l)
进行超参数调优
YOLO 章节总结¶
本章介绍了YOLO系列目标检测算法的发展历程和核心技术:
1. 目标检测基础
目标检测的定义和应用场景
两阶段 vs 一阶段检测方法
2. YOLOv1
网格划分和边框预测
输出层含义()
损失函数设计
3. YOLOv2/v3
Anchor机制和K-means聚类
多尺度检测
边框解码公式
4. YOLOv5
数据增强策略(Mosaic、MixUp等)
网络结构(Focus、CSP、FPN+PAN)
正负样本匹配策略
5. 损失函数演进
IOU → GIOU → DIOU → CIOU
NMS优化

交互式CIFAR-10演示资源¶

ConvNetJS CIFAR-10演示:https://
CNN解释器交互工具¶

CNN解释器:https://

可视化快照 I¶












卷积神经网络总结¶
本章全面介绍了卷积神经网络(CNN),涵盖从基本概念到高级架构和应用。
核心概念: 首先解释了CNN背后的动机,并与人类视觉系统进行了类比。介绍了卷积层、池化层、填充和步长等关键组件作为基础构建块。
架构演进: 本章追溯了具有影响力的CNN模型的历史发展,从开创性的LeNet开始,逐步介绍了标志性架构,如AlexNet、VGG、GoogLeNet(及其Inception模块)、ResNet(引入残差连接)和DenseNet(密集连接)。
实践实现: 一个动手示例演示了如何使用PyTorch在CIFAR-10数据集上构建和训练CNN进行图像分类,提供了实用的编程见解。
YOLO目标检测: 相当篇幅专门介绍了YOLO(You Only Look Once)目标检测器系列。涵盖了从YOLOv1到YOLOv5的演变,详细介绍了关键创新,如锚框、多尺度预测以及损失函数的演进(从IOU到CIOU)。
可视化与应用: 本章最后展示了可视化和解释CNN学习内容的方法,并简要介绍了目标检测、OCR和图像生成等多种应用。